
K8s controllers and operators
In k8s world every resource created via controller. Like there are inbuilt controllers for pods, deployments , replica set etc. So basically, Controllers are nothing but a control loop that continuously monitor the state of the cluster and take actions to bring the cluster into the desired state. The resources have a spec that provides the desired state. The controller checks the current states. If it doesn’t match the desired state, it will make the appropriate changes or modifications to bring it closer to the desired state.
Different types of Kube-Controller-Manager
-
ReplicaSet Controller: This controller is responsible for maintaining a stable set of replica Pods running at any given time. It is often used in conjunction with Deployments to ensure that a specified number of pod replicas are running at all times, even in the event of node failure or pod termination.
-
Deployment Controller: This controller provides declarative updates for Pods and ReplicaSets. It allows for easy scaling, rolling updates, and rollbacks of applications. The Deployment controller manages the creation and deletion of ReplicaSets to ensure the desired number of pods are always running.
-
StatefulSet Controller: This controller is used for managing stateful applications, such as databases. It provides unique identity (a stable hostname) to each pod in the set and maintains the order and uniqueness of these pods. It’s particularly useful when you need stable network identifiers, stable persistent storage, and ordered, graceful deployment and scaling.
-
Service Controller: This controller is responsible for maintaining a stable IP address and DNS name for a set of pods. It acts as a load balancer and routes traffic to the appropriate pods based on the service’s selector. This ensures that services have a stable endpoint for accessing the running pods, even as they are created, destroyed, or moved around the cluster.
Behaviour and Architecture
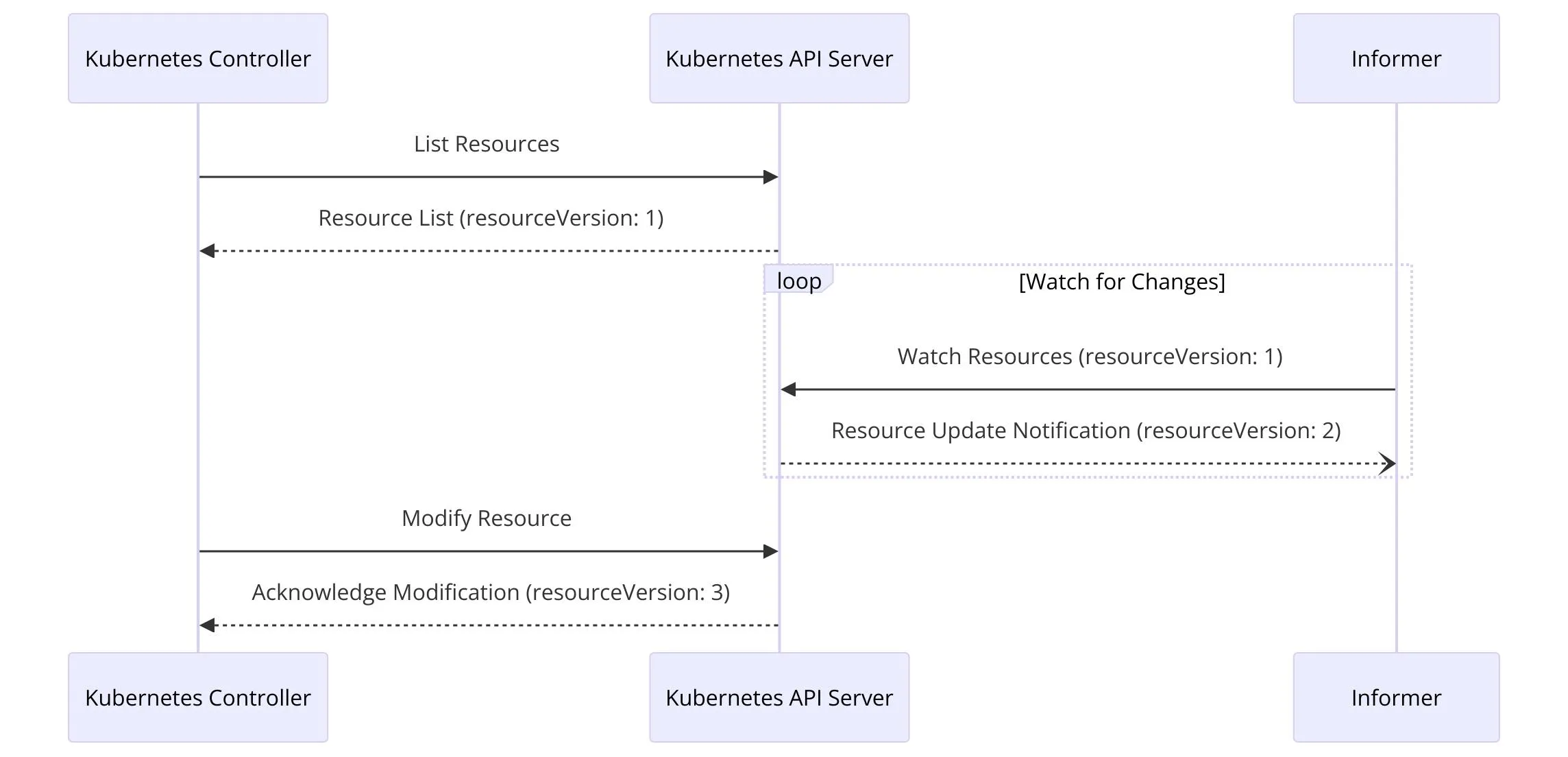
So Before diving into testing, we have to understand the basic architecture of a standard controller. In the client-server architecture of Kubernetes, controllers play a crucial role as clients that make API calls, primarily HTTP, to the Kubernetes API server. Their main objective is to reconcile Kubernetes API objects with the actual system resources. An essential component in this architecture is the use of Informers. Informers are responsible for monitoring any changes in the cluster, which is crucial because continuous polling to retrieve information on resources can significantly degrade the performance of the API server.
Informers work by querying the resource data and storing it in a local cache. Once the data is stored, an event is generated only when there is a change in the state of an object (or resource). This approach ensures that the system is not overwhelmed by unnecessary events and that the controller is only notified when a relevant change occurs.
Another important concept in this architecture is the resource version. This version changes with every write operation and is used for optimistic concurrency control. It ensures that updates to resources are managed in a way that avoids conflicts and maintains consistency across the system. By understanding and leveraging these mechanisms, Kubernetes controllers can efficiently manage and reconcile the state of resources in a cluster.
Custom CRDs and Controllers in Kubernetes
Kubernetes allows for the creation of Custom Resource Definitions (CRDs), which are extensions of the Kubernetes API that enable users to define custom resources. These custom resources are not available in a default Kubernetes installation and are used to accommodate domain-specific use cases and complex application requirements.
To manage these custom resources, a custom controller is required. The custom controller, CRD, and Kubernetes API server form a cohesive relationship where:
-
The CRD defines the custom resources.
-
The API server manages the lifecycle of these resources.
-
The custom controller ensures that the state of these resources is maintained according to the desired configuration.
This architecture enables the extensibility of Kubernetes, allowing users to tailor the platform to their specific needs.
Testing of a controller –
Ensuring that a Kubernetes controller is ready to serve requests to the Kubernetes API server is crucial before deploying it to production. There are several approaches to testing Kubernetes controllers. Some of them I mentioned are from the article :
-
Using client-go fakes or higher-level abstractions: This approach avoids running any backing API, making it suitable for unit testing individual components in isolation.
-
Using the envtest package from controller-runtime: This package works with a pared-down API server to validate real interactions with the API, including timing and cache syncs, without interference from other controllers. It supports both local testing against a pared-down instance and testing against a fully functional cluster.
-
Running a real API server: This approach is suitable for staging environments or instances like ephemeral kind or microk8s for testing real outcomes. It allows for testing interactions against a real API server.
The advantage of using an external process, such as envtest or a real API server, is that it accounts for the latency inherent in a distributed system. Libraries like Gomega can be used to wait for specific conditions after an action occurs.The above approaches are more often sounds best for unit testing and integration level testing, where we are testing a particular component in isolation. either by faking out the data by writing tests
While the above techniques are effective for unit and integration testing, they may not cover end-to-end (e2e) testing, which is crucial for ensuring the overall functionality of the controller. One approach to e2e testing is to perform resource updates and other operations to test the entire flow of the controller in a controlled environment, replicating the process whenever necessary. This helps validate the controller’s behaviour in real-world scenarios and ensures that it is ready for production deployment.
In summary, a combination of unit, integration, and end-to-end testing is essential for ensuring the reliability and effectiveness of Kubernetes controllers before pushing them into production.
Why test kubernetes controllers with Keploy?
Building and testing Kubernetes controllers locally can be challenging, especially when dealing with outgoing API calls. However, Keploy, as a tool creates test cases and data mocks from API calls, DB queries, etc., offers a solution. Keploy allows you to record and replay outgoing calls made by your Kubernetes controller, which can be incredibly useful for testing and ensuring that your controller behaves as expected.
You might be wondering how this is possible without any code changes. Keploy uses eBPF to add probes to the kernel space and collect network buffer data. This data is then sent to Keploy’s proxy, which acts as a userspace where all the processing of the buffer is done by different protocol parsers. Keploy can capture the egress traffic of the controller and store the request and response in a YAML file for that particular event. During replay mode, instead of making the API call to the real API server, Keploy will return the response from the stored YAML file for that particular request. This makes the process independent of the cluster or environment, offering a convenient and efficient way to test Kubernetes controllers locally.
Recording Outgoing Calls
So for capturing the tests of your controllers locally or from any live environment you have to first start the kubernetes cluster and make your custom controller to make some interaction with the server.
To record your controller with Keploy, follow these steps:
-
Set your Kubernetes
*rest.Configobject to be insecure and without a CA file:cfg.Insecure = true cfg.CAFile = "" -
Create a custom
RoundTripperto add a header field containing the resource version. This header serves as a trace-id for matching requests during the same state with recorded mocks. Here’s an example implementation:type customRoundTripper struct { rt http.RoundTripper } func (crt *customRoundTripper) RoundTrip(req *http.Request) (*http.Response, error) { ctx := req.Context() rsv := ctx.Value("ResourceVersion") if rsv != nil { req.Header.Add("keploy-header", rsv.(string)) } return crt.rt.RoundTrip(req) } cfg.WrapTransport = func(rt http.RoundTripper) http.RoundTripper { return &customRoundTripper{rt: rt} } -
Ensure to set the resource version value in
context.Contextduring the sync process. This is crucial for passing the modified context to the update and create methods of your controller. For example:func (c *Controller) syncHandler(ctx context.Context, key string) error { // set ResourceVersion in ctx rv := foo.GetResourceVersion() if rv != "" { ctx = context.WithValue(ctx, "ResourceVersion", rv) } } -
Build the Go binary of your Kubernetes controller:
go build -o sample-controller . -
To record the outgoing calls via Keploy, wrap your controller command with Keploy’s record command. Note – This feature of keploy is in beta use and not yet released in main. This was specifically created as an experiment for the Kubernetes enthusiasts to try and give reviews upon. So you have to checkout in this specific branch and build the keploy binary using go build command. https://github.com/keploy/keploy/pull/1342.
-
Checkout in the specified branch.
-
git checkout kube-controller
-
-
Building the keploy binary for that branch.
go build -o keploy && sudo mv keploy /usr/local/bin
-
-
Add the necessary flags according to your kube config:
sudo -E env PATH=$PATH keploy record -c "./sample-controller -kubeconfig=$HOME/.kube/config" --mtls-cert-path "$HOME/.minikube/profiles/minikube/client.crt" --mtls-key-path "$HOME/.minikube/profiles/minikube/client.key" --mtls-host-name 192.168.49.2:8443 -
You can see
keploy/test-set-0/mocks.yamlcreated as soon as Keploy starts intercepting the outbound calls. Each resource version has a separate mock file denoted withmocks_ + "<resource_version>".
Note – One thing which I want to clear is that, above feature doesn’t help you in TDD (Test driven development). But you can still keploy while writing unit tests by leveraging the stub generation capability of keploy. So instead of making any mock api server or writing stub for a particular unit test, you can once play that test in your real environment . Keploy will store all the interactions in mock file and will use that data when next time the tests are run.
Testing with Recorded Mocks
To test your controller with recorded mocks:
-
Run Keploy in test mode with the
mockAssertflag set to true and provide your controller binary. Keploy will automatically create a fake kube config for you:sudo -E env PATH=$PATH keploy test -c "" --mockAssert true -
Optionally, you can set your own replay time, which will try to replay your recorded session within the provided time: complete sample app integrated with keploy is given here.
keploy test -c--mockAssert true --replaySession 100 -
Note that the replaying process trims the large enough event time gap to a precise average duration between the two events of the informers. This allows events to be sent earlier than they occurred in the record, facilitating a faster replay.
-
This can help you replay the whole session of api calls produced by the controller but this time you don’t need real k8s server or any external source to get the response. All the responses will be returned by the keploy itself acting like a mock server or a middleman. This can give a confidence to run it in your CI-CD pipelines.
-
For eg – You work in a large cloud computing organisation and to get all things deployed it requires lot of virtualization and is resource intensive operation. So its nearly impossible to test it in a real environment. Here Keploy like tool can be very useful as it has already the response which you want to get in case of a successful rollout of that resource. So it can be fast, reliable and cost saving operation as you just have capture the right flow of your controller service only one time. And can re-use the keploy replay in your subsequent releases.
Conclusion
Testing Kubernetes controllers locally can be made more efficient and reliable with tools like Keploy. By recording and replaying outgoing calls, you can ensure that your controller behaves correctly in various scenarios, improving the overall quality of your Kubernetes applications. Since keploy have native support of testing frameworks like gotest , its also possible to get the line coverage of any application even of your kube controller. Explore Keploy and enhance your Kubernetes controller testing workflow!
FAQs
What are the advantages of using Keploy for testing Kubernetes controllers?
Keploy simplifies testing Kubernetes controllers by:
-
Recording and replaying outgoing API calls: This eliminates the need for live environments during testing.
-
Improved efficiency: By using stored mocks, testing becomes faster and independent of the actual Kubernetes cluster.
-
Cost and resource savings: It reduces dependency on resource-intensive environments for validation, making it ideal for CI/CD pipelines in large-scale operations.
How does Keploy handle outgoing API calls for Kubernetes controllers?
Keploy uses eBPF probes to intercept outgoing calls and stores request-response pairs in mock files. During replay mode:
-
Calls are intercepted and matched with previously recorded mocks.
-
Responses are returned from these mocks instead of reaching out to the actual API server.
This mechanism ensures tests can run without needing a live Kubernetes cluster.
Can Keploy be used for Test-Driven Development (TDD) with Kubernetes controllers?
While the recording and replay feature of Keploy is not designed specifically for TDD, it can still be used effectively:
-
Stub generation: Run the controller in a real environment once to capture interactions. Keploy will create mocks for subsequent use.
-
Unit testing support: By leveraging these mocks, you can avoid writing stubs manually and focus on test execution.
Keploy complements existing TDD workflows by streamlining mock creation and reducing development overhead.

Leave a Reply