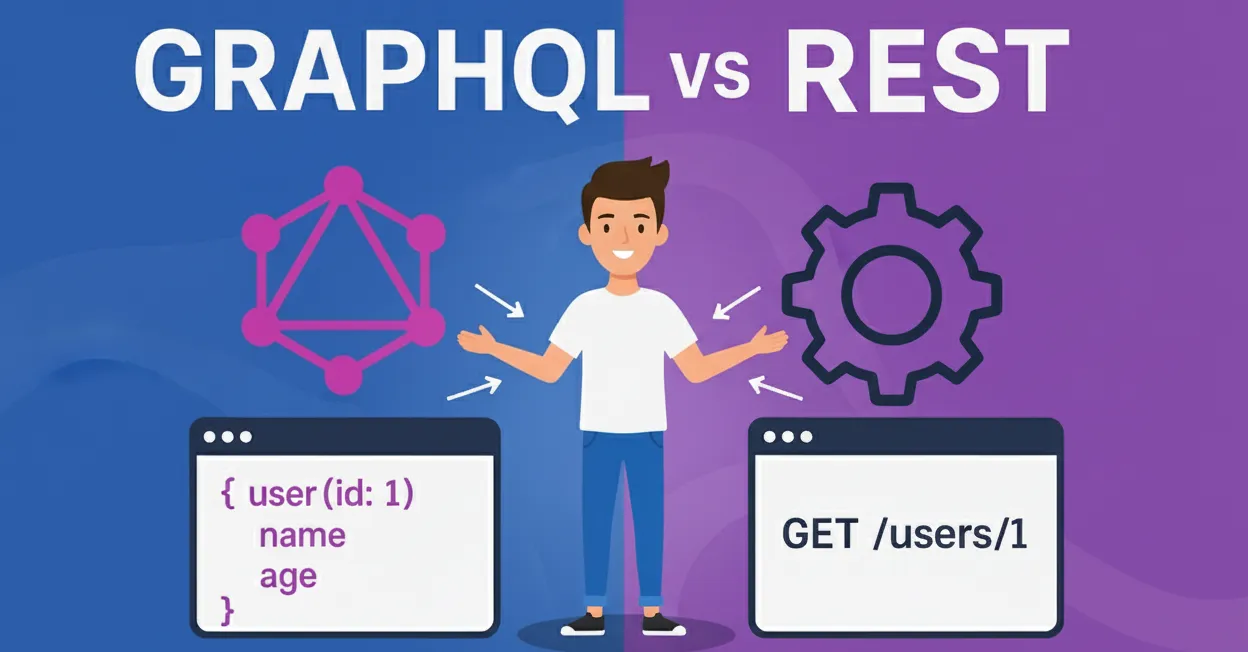
In the current ecosystem of web and mobile apps, APIs are the ‘glue’ that connects clients and servers. We find two key paradigms of APIs: REST vs GraphQL, which have emerged as the primary methods of communicating data between applications. Each has strengths and weaknesses, and that choice is significant, as each has dramatic implications for the performance, scalability, and flexibility of your applications. This blog explores REST vs GraphQL deeply, what they have in common, and how they diverge and shares some real-world examples
What is REST?
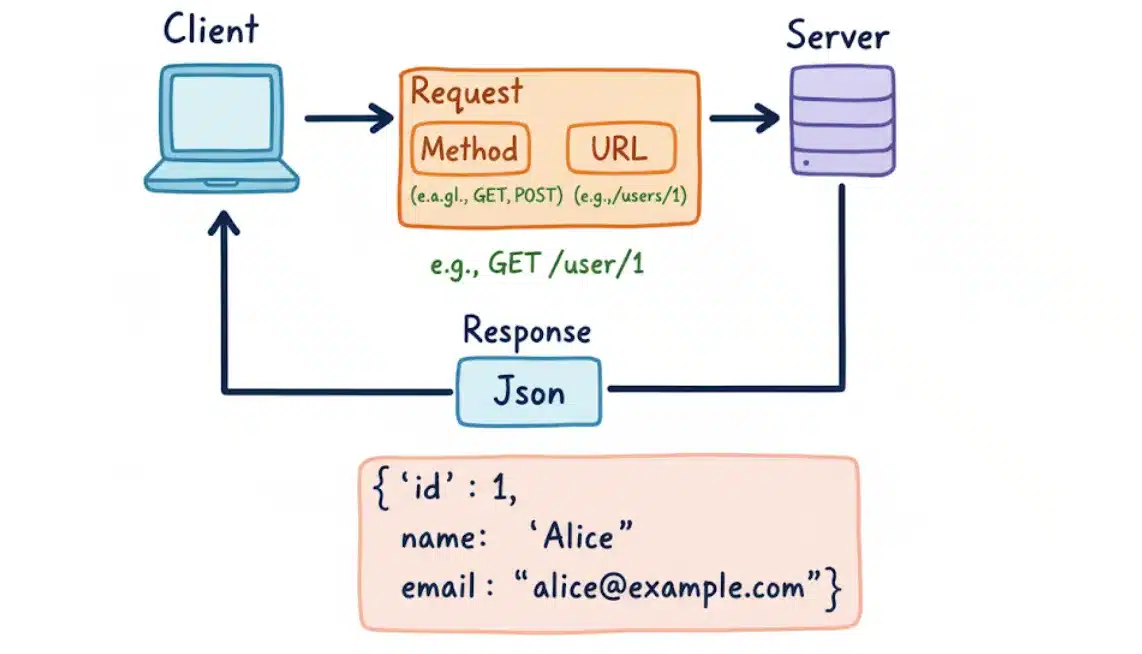
REST (Representational State Transfer) is a method of developing APIs. With REST, you send requests for resources using standard HTTP methods: GET, POST, PUT, and DELETE. Each resource is identified by a unique URL.
- How it works: With REST, you have multiple endpoints (URLs) and each endpoint is mapped to a different resource. To get different pieces of information, usually you have to make multiple requests to multiple endpoints. For example, to get a user’s posts, you might first hit /users/id for the user information and then hit /users/id/posts for their posts.
Key principles of REST:
-
Resources and URLs: Everything is a resource, and every resource is uniquely identifiable with a URL.
-
HTTP Methods (CRUD): We interact with resources using standard methods e.g, Get, Post, Put, Patch, Delete
-
Stateless: Every client request contains all the information; Servers do not store the state on the client.
-
Resource Representations: Each resource can be represented by a JSON or XML.
-
Client-Server Separation: The client sends the request and handles the interface, while the functionality and any data are managed by a server.
-
Uniform Interface: Accessing and modifying resources all look the same, which helps make an API predictable and easy to use.
Basic operations of REST:
Request format
- Get All Resources
powershell
GET /resourcesThis returns the list of all resources.
2. Get a Specific Resource
powershell
GET /resources/{id}It returns details for the resource identified by id.
- Add a Resource
powershell
POST /resourcesIt creates a new resource. You send data in the request body.
- Update Resource
powershell
PUT /resources/{id}It updates the resource identified by id.
- Delete Resource
powershell
DELETE /resources/{id}This deletes the resource identified by id.
Response format
REST usually returns an HTTP status code and a raw JSON body of data (or error messages).
Example (Get User with ID 1):
json
{
"id": 1,
"name": "Alice",
"email": "alice@example.com"
}Example (if Error):
json
{
"message": "User not found"
}There is no wrapper, just direct data or a message.
In REST, every baseline operation maps to an endpoint and standard HTTP method that makes it simple, consistent, and easy to use.
Benefits of REST
-
Simple to Use: REST relies directly on HTTP, and therefore most developers will find REST to be simple and intuitive to use.
-
Efficient Caching: REST is able to take advantage of HTTP caching, which allows apps to use stored responses and therefore load faster.
-
Good Scalability: Because a REST system has a clear separation of client and server, it can scale independent parts of the system differently.
-
Great Compatibility: REST is found almost everywhere programming languages, frameworks, and tools so it is very easy to integrate with.
Limitations of REST
-
Excessive Data: Occasionally, too much data is returned to the client in a REST response and, therefore, it is inefficient.
-
Multiple Calls: In other cases, multiple calls to the API are necessary in order to retrieve all of the needed data.
-
New Endpoints and Versions: Whenever new fields or features are added, REST APIs will generally need to be extended by creating new endpoints or new managed versions.
-
Version Management: For any major changes made to REST APIs, versioning is needed (/v1/, /v2/)… which can add costs to your maintenance workload.
REST is great as a simple and stable API, but if your application is highly dynamic or data-heavy, you may run into challenges.
What is GraphQL?
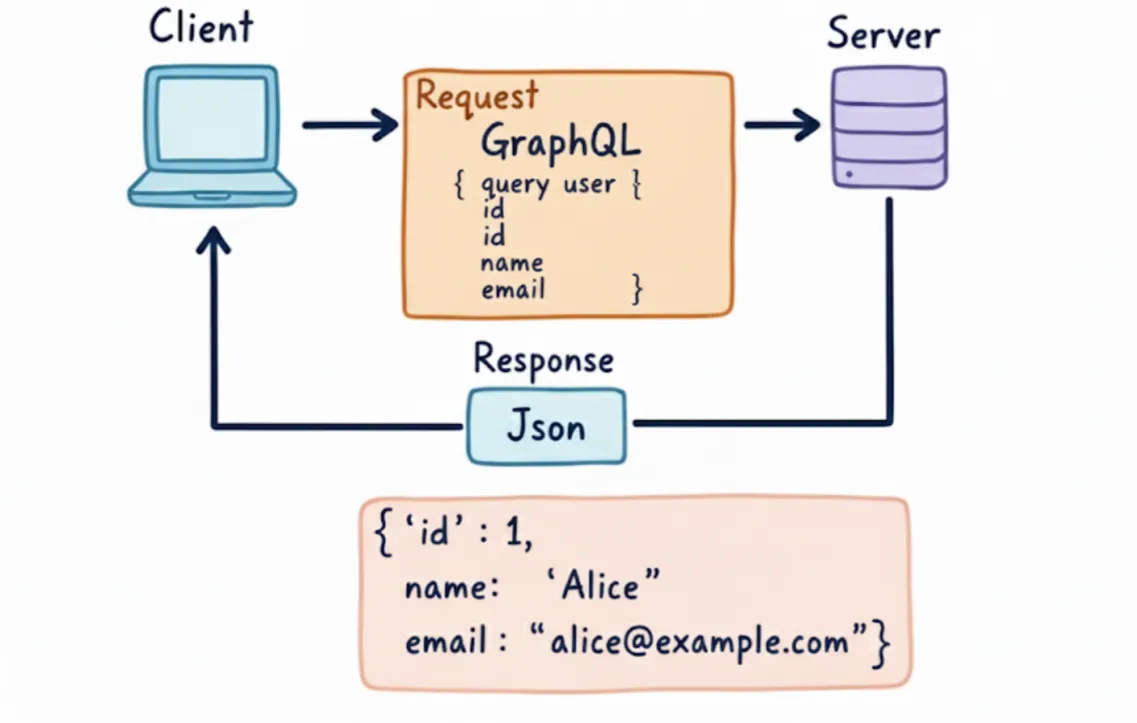
GraphQL is a query language and runtime for APIs that allows clients to request exactly the information they need from a single endpoint (usually /graphql). Instead of multiple endpoints like REST, GraphQL uses queries to get information and mutations to update data.
- How it works: With GraphQL, you usually have a single endpoint. You send a query to an endpoint that explains exactly what data you want. The server sends back a JSON object that corresponds to your precise query.
Key principles of GraphQL
-
Single Endpoint Everything is done through one endpoint (generally /graphql).
-
Queries and Mutations: Queries pull data, mutations push data.
-
Exact Data Fetching: Clients only request the fields they want to receive.
-
Strongly Typed Schema: Every field and operation is defined in a schema with type strictness.
-
Introspection: Clients can explore the schema to know what queries and mutations are available.
Basic operations in GraphQL:
Request Format
- Query – Get All Resources
graphql
{
resources {
id
name
details
}
}You can get all of the resources using only the fields you requested.
- Query – Get a Specific Resource
graphql
{
resource(id: 123) {
name
details
}
}You can get details of a specific resource by ID and the fields you requested.
- Mutation – Add a Resource
graphql
mutation {
addResource(name: "Sample", details: "Example") {
id
name
}
}You can add a resource and only get the fields you requested.
- Mutation – Update Resource
graphql
mutation {
updateResource(id: 123, name: "Updated") {
id
name
}
}You can update a resource and have it return fields that you want.
- Mutation – Delete Resource
graphql
mutation {
deleteResource(id: 123) {
success
message
}
}You can delete a resource and get a response back.
Response Format
GraphQL always wraps the response inside a data (and optionally errors) field.
Example (Get User with ID 1):
json
{
"data": {
"user": {
"id": 1,
"name": "Alice",
"email": "alice@example.com"
}
}
}Example (if Error):
json
{
"errors": [
{
"message": "User not found",
"locations": [{ "line": 2, "column": 3 }],
"path": ["user"]
}
],
"data": {
"user": null
}
}GraphQL responses are always structured with data and/or errors.
In GraphQL, you use a single endpoint and request the data you want based on your queries, and avoid over-fetching or under-fetching data.
Benefits of GraphQL
-
Custom Data Retrieval: Clients are able to request only the fields they need. There is no chance of over-fetching or under-fetching data.
-
Strongly Typed Schema: GraphQL has defined data types, so errors are caught in earlier development, which leads to higher reliability in later development.
-
In-Built Real-Time Functionalities: Subscriptions can provide real-time updates, which is great for making apps for chats, stocks, notifications, etc.
-
Hierarchical Organization: Queries reflect the shape of the returned data making responses predictable.
Limitations of GraphQL
-
High Learning Curve: Developers have to become schema designers and have to learn resolvers, which can be extremely frustrating for new developers or teams.
-
Hard Caching: In REST, HTTP has known exit points, and every payload is known in advance. GraphQL’s flexibility makes caching difficult.
-
Overhead with small applications: For instance, with small apps, GraphQL introduces even more overhead and complexity, along with the additional setup.
-
Performance Hits: Poorly designed queries within GraphQL, given the significant customization capabilities, can slow down performance, as they may overload the server more and utilize more server resources than initially estimated.
Key Differences Between GraphQL and REST
| Aspect | REST | GraphQL |
|---|---|---|
| Endpoints | It has multiple resource endpoints like /books and /authors. | It has just a single endpoint: /graphql. |
| Data Fetching | It makes fixed responses, which can cause either over-fetching or under-fetching. | Clients get to specify exactly which fields they want, so there is rarely if ever over-fetching or under-fetching. |
| Versioning | You typically have to use versioning when you introduce changes—/v1/, /v2/, etc. | There is usually no need for versioning, because the schema can be flexible to evolve. |
| Caching | It supports caching in a standard HTTP way, making it straightforward to cache a response. | The caching can be more complex and usually requires custom sources. |
| Performance | You may be required to make multiple calls to the API, just to get data related to another call. | You often get to make fewer calls to get the needed data, since it is all encapsulated in one query. |
| Learning Curve | It has an easy learning curve, and is beginner friendly. | The learning curve is moderate to steep. |
| Real-time Support | It has minimal support for real-time, requiring either WebSockets or SSE for live updates. | You get built in support for real-time through subscriptions. |
| Error Handling | Errors are handled by HTTP status codes (404, 500, etc.). | Errors are returned instead as part of the query response. |
Similarities Between GraphQL and REST
Both share some fundamental principles, despite the differences:
-
Both use HTTP as the transport protocol.
-
Both support CRUD operations.
-
Both need authentication and authorization.
-
Both provide data transfer from the server to the client.
-
Both may be secured by SSL/TLS and with tokens.
When to Use REST vs. GraphQL
Use REST in circumstances in which:
-
The API is simple and stable that wont often change the schema.
-
Caching is important, REST convention works well with the typical HTTP request & responses.
-
You want a simple and easy learning curve, to help onboard new developers.
-
The system is internal, limited and not data heavy.
Use GraphQL in situations in which:
-
You must support multiple clients and data needs (e.g., web, mobile or IoT).
-
You want to minimize and restrict the network traffic.
-
Only fetching fields that will be required for use. Real-time data updates are critical, for example: chats, notifications, live dashboards.
-
Data has to collected from multiple sources and/or microservices to return a single response.
Challenges with REST and GraphQL
Both REST and GraphQL provide great ways to offer API services, but both have their challenges:
Challenges with REST
-
Overfetching or Underfetching: Clients can sometimes receive more data than they need, or need to make multiple calls back and forth just to get the data they need.
-
Rigid Endpoints: In most cases, if a field is added, or an existing returned field is changed, they have to create a different endpoint for that information, or contend with versioning.
-
Versioning: It doesn’t take long to end up with a lot of versioned APIs – /v1/, /v2/, etc. – it can get messy, quickly.
-
Real-time Limitation: Although you can obtain some level of real-time using WebSockets, or other means, you don’t get real-time support out of the box.
Challenges with GraphQL
-
Learning Curve: Developers may have to learn more about schemas, resolvers, and the query structure (may sound a little different).
-
Caching: Flexible queries that GraphQL offers will make caching a lot more difficult than REST, whose URLs are structured more predictably.
-
Performance risk: Misguided queries can request more data at once than is possible in total, which would slow the server down.
-
Unnecessary overhead for small services: If they want to develop a simple API, then that setup of the GraphQL components may cause them to take unnecessarily more time.
Real-World Examples with Code
REST API in Python (Flask)
A REST API in Flask uses multiple endpoints like /users or /users/<id> to perform CRUD operations. Each HTTP method (GET, POST, PUT, DELETE) maps directly to an action on the resource.
Install first:
python
pip install flask graphene flask-graphqlCode:
python
from flask import Flask, request, jsonify
app = Flask(__name__)
# Sample data
users = [
{"id": 1, "name": "Alice", "email": "alice@example.com"},
{"id": 2, "name": "Bob", "email": "bob@example.com"}
]
# Get all users
@app.route("/users", methods=["GET"])
def get_users():
return jsonify(users)
# Get a specific user
@app.route("/users/<int:user_id>", methods=["GET"])
def get_user(user_id):
user = next((u for u in users if u["id"] == user_id), None)
return jsonify(user) if user else ({"message": "User not found"}, 404)
# Add a new user
@app.route("/users", methods=["POST"])
def add_user():
new_user = request.json
new_user["id"] = len(users) + 1
users.append(new_user)
return jsonify(new_user), 201
# Update a user
@app.route("/users/<int:user_id>", methods=["PUT"])
def update_user(user_id):
user = next((u for u in users if u["id"] == user_id), None)
if not user:
return {"message": "User not found"}, 404
data = request.json
user.update(data)
return jsonify(user)
# Delete a user
@app.route("/users/<int:user_id>", methods=["DELETE"])
def delete_user(user_id):
global users
users = [u for u in users if u["id"] != user_id]
return {"message": "User deleted successfully"}
if __name__ == "__main__":
app.run(debug=True)Running the App
python
python app.pyWhen you start your Flask app with ‘python app.py’, you’ll see something like this in the terminal:
python
* Running on http://127.0.0.1:5000
Press CTRL+C to quit
* Restarting with watchdog (windowsapi)
* Debugger is active!
* Debugger PIN: 139-703-176This means that your API is up and running locally at http://127.0.0.1:5000. Let’s go ahead and test it out with cURL.
Testing Queries (REST)
Open a new terminal where the Flask server is running.
1. Get all users
python
curl http://127.0.0.1:5000/usersOutput:
python
[
{
"id": 1,
"name": "Alice",
"email": "alice@example.com"
},
{
"id": 2,
"name": "Bob",
"email": "bob@example.com"
}
]Explanation: Returns a list of all users in the system.
2. Add a new user
python
curl -X POST http://127.0.0.1:5000/users \
-H "Content-Type: application/json" \
-d '{"name":"Charlie","email":"charlie@example.com"}'Output:
python
{
"id": 3,
"name": "Charlie",
"email": "charlie@example.com"
}Explanation: Creates a user named Charlie and gives them a unique ID.
Great! Now that you’ve seen how to get all of the users and add a new user, it’s your turn to try the other operations yourself:
-
GET /users/<id> → fetch a single user by ID
-
PUT /users/<id> → update user details
-
DELETE /users/<id> → remove a user
GraphQL API in Python (Flask + Graphene)
A GraphQL API in Flask (with Graphene) uses a single endpoint /graphql to handle all requests. Clients define queries and mutations to fetch or modify exactly the data they need.
Install first:
python
pip install flask==2.3.2
pip install graphene==2.1.9
pip install flask-graphql==2.0.1These versions are compatible and avoid common import errors with graphql-core.
Code:
python
from flask import Flask
from flask_graphql import GraphQLView
import graphene
from collections import namedtuple
from collections.abc import MutableMapping
# Sample Data
users = [
{"id": 1, "name": "Alice", "email": "alice@example.com"},
{"id": 2, "name": "Bob", "email": "bob@example.com"}
]
# User Type
class User(graphene.ObjectType):
id = graphene.Int()
name = graphene.String()
email = graphene.String()
# Queries
class Query(graphene.ObjectType):
users = graphene.List(User)
user = graphene.Field(User, id=graphene.Int())
def resolve_users(root, info):
return users
def resolve_user(root, info, id):
return next((u for u in users if u["id"] == id), None)
# Mutations
class AddUser(graphene.Mutation):
class Arguments:
name = graphene.String()
email = graphene.String()
user = graphene.Field(lambda: User)
def mutate(self, info, name, email):
new_user = {"id": len(users) + 1, "name": name, "email": email}
users.append(new_user)
return AddUser(user=new_user)
class Mutation(graphene.ObjectType):
add_user = AddUser.Field()
# Set up Schema
schema = graphene.Schema(query=Query, mutation=Mutation)
# Set up Flask app
app = Flask(__name__)
app.add_url_rule(
"/graphql",
view_func=GraphQLView.as_view("graphql", schema=schema, graphiql=True)
)
if __name__ == "__main__":
app.run(debug=True)Running the App
Open your terminal and run:
python
python app.pyYou should see output like this:
python
* Running on http://127.0.0.1:5000/
* Restarting with watchdog (windowsapi)
* Debugger is active!
* Debugger PIN: 139-703-176This indicates the server is running successfully.
Testing Queries (GraphQL)
Open your browser and go to:
python
http://127.0.0.1:5000/graphqlYou can try pasting the following GraphQL operations:
1. Get all users
python
query {
users {
id
name
email
}
}Output:
python
{
"data": {
"users": [
{"id": 1, "name": "Alice", "email": "alice@example.com"},
{"id": 2, "name": "Bob", "email": "bob@example.com"}
]
}
}2. Add a new user
python
mutation {
addUser(name: "Charlie", email: "charlie@example.com") {
user {
id
name
email
}
}
}Output:
python
{
"data": {
"addUser": {
"user": {
"id": 3,
"name": "Charlie",
"email": "charlie@example.com"
}
}
}
}You can try other queries like fetching a user by ID or experimenting with mutations in GraphQL.
How to Test Your APIs Without Writing Any Code
In this blog, we’re talking about the debate between Rest vs GraphQL, right? We use both Rest and GraphQL in our projects. Let’s say you want to test your Rest APIs how do you check whether they are working fine or not? We manually write the test cases and verify them using assertions, right?
That’s fine for small projects, but what if there are so many APIs? How do you test them all? And what about the edge cases for the APIs?
Why worry when Keploy is here for API testing? Keploy provides you with a platform to create API test cases without writing any code or interacting with any SDKs. You heard it right the Keploy API Testing platform gives you API test cases that work for your application, including edge case scenarios too.
Curious about how it works? All you have to provide is:
-
cURL commands or a Postman collection
-
An OpenAPI schema
-
Your application URL (localhost also works)
Keploy will automatically create your API test cases and verify the test cases by running them against your application. In the end, you’ll have test cases that work for your application, and you can also run API testing in your CI/CD pipeline.
This is how the dashboard would look like.
So, why wait? Go to app.keploy.io to create your test cases. Trust me, you will definitely like it.
Also, there is another way to create test cases by actually recording them. Yes, with the Keploy Chrome extension, you can record the API calls and create test cases to test them all without writing any code.
To Know more about Keploy Chrome Extension:Check out here
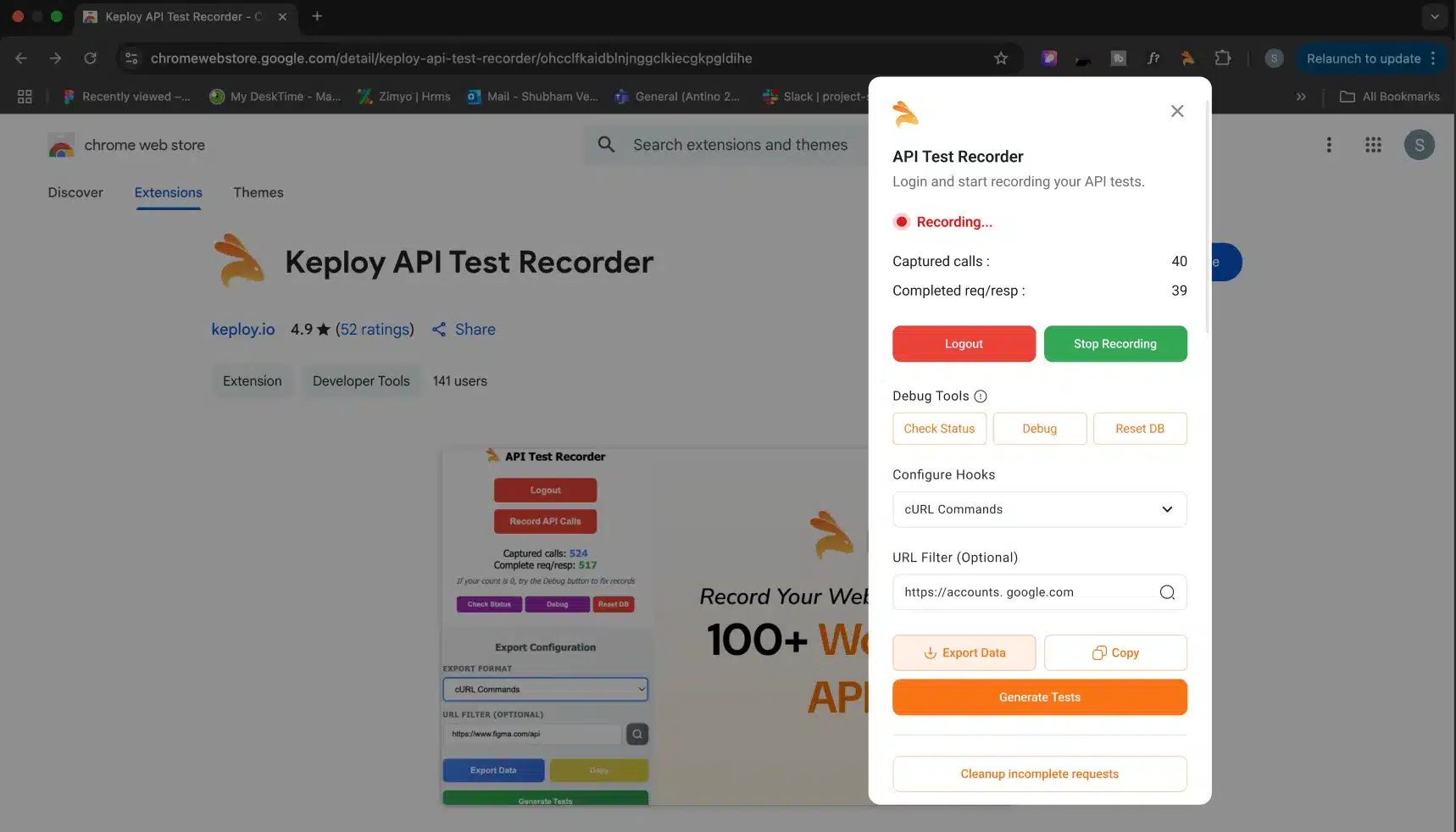
Conclusion
REST and GraphQL are powerful tools for building APIs, but they are tailored to different conditions. REST is easy to use, a reliable system, and perfect for smaller applications (or systems) that need caching and stability. GraphQL is flexible, efficient, and offers real-time functionality; therefore is best suited for modern applications, with multiple clients and more complex schemas. It’s up to you to decide on your project requirements, or even a hybrid approach that can provide you with the best of both worlds.
FAQs:
-
Will GraphQL completely replace REST?
No. REST is still widely alive, and GraphQL is an option for when your needs are more complex.
-
Which one is easier for beginners?
REST. Because it is simpler and easier to understand and learn than the schema-driven and typed approach of GraphQL.
-
Do I always need GraphQL for real-time apps?
Not necessarily. REST can use WebSockets, but GraphQL has a built-in subscription system to handle this in a manner that is both readable and performant.
-
Which scales better, REST or GraphQL?
Both easily scale, but GraphQL proactively reduces network calls to retrieve the same data, making it better for performance in large, multi-client systems.
-
Is it possible for a project to use both REST and GraphQL?
Absolutely! There’s nothing stopping modern apps from using REST for simple CRUD task, and GraphQL to retrieve more complex and detailed data.

Leave a Reply