Manual testing can’t keep up with today’s fast-moving, AI-powered software development.
Test automation isn’t just about saving time-it’s about surviving in a landscape where releases happen daily and bugs can cost millions. Now since AI-generated code is increasing, quality control and ownership becomes more important. From the classic Testing Pyramid to modern takes like the Honeycomb and Trophy, automation strategies are evolving fast. This guide dives into what works now, what’s outdated, and how AI-driven tools like Playwright, Keploy, Co-pilot etc.. are reshaping how teams test in the real world of AI-era.
What I’ve Learned About Test Automation After Talking to 2000+ Engineering Teams This Year
Over the past few years, I’ve sat in rooms (and Zooms) with engineering teams from scrappy startups to Fortune 500, 100 giants, all wrestling with the same question: how do we ship fast without breaking things?
In theory, “just automate the tests” sounds simple. In practice, I’ve seen it stall for months-or even fail- because the approach didn’t match the team’s reality.
From my own surveys and conversations, here’s what stood out:
-
Automation isn’t just about speed – it’s about confidence!
Teams that treat test automation as a safety net (run on every commit, integrated into CI/CD) recover from production issues faster and take bolder bets with refactoring. The best engineering leaders I spoke to view automation as a risk management tool, not a cost-cutting hack.
-
Too many unit tests can slow you down.
Multiple leaders admitted that an over-reliance on unit tests actually discouraged refactoring. Why? Because every time the implementation changed – even if the behavior didn’t – dozens of brittle unit tests broke and had to be rewritten. In contrast, more integration tests encouraged refactoring because they validated behavior at the service boundary, not the implementation details.
-
Unit tests aren’t always the ROI king.
In legacy-heavy or microservices-based systems, many devs admitted their unit test coverage was “great on paper, useless in reality.” Integration tests and API contract tests often gave them higher confidence because they caught the real-world failures unit tests missed.
-
Flaky tests can kill adoption.
One fintech team told me they had “more Slack fights about flaky end-to-end tests than about production outages.” Automation without stability is a morale drain. The high-performing teams invested early in test maintenance – regularly pruning or rewriting flaky tests.
-
Manual testing isn’t dead – it’s just repositioned.
Senior QA leads consistently said they now spend 80% less time on regression and far more on exploratory, usability scenarios. Automation freed them to think instead of click.
-
Tooling matters less than test design.
Across Selenium, Playwright, Cypress, Keploy and AI-driven tools, the success stories came from teams that first nailed their test strategy – knowing what to automate and why. Poor strategy with a great tool still failed.
And here’s where AI is changing the game:
AI-assisted test generation, like what Co-Pilot, Keploy, Playwright enables, is reducing the barrier to creating integration tests that don’t rot in the repo. Teams that once avoided integration-level automation due to complexity now spin up realistic tests in hours, not weeks.
In short: Test automation isn’t a checkbox. It’s a living part of your engineering culture. And the teams winning with it treat it as an evolving practice – not a one-time project.
What Is Test Automation (Really)?
I’ve found that when you ask 10 engineering leaders to define test automation, you’ll get at least 12 answers.
At its core, yes – it’s about using software to run tests automatically with minimal human intervention. But in practice, it’s about something bigger: creating a feedback loop that gives teams the confidence to move fast without tripping over hidden regressions.
The high-performing teams I’ve worked with don’t talk about “automating tests” as a task – they talk about automating trust. They want to know that when they merge a pull request at 4:55 PM, the only thing keeping them from a calm evening isn’t a missed edge case.
And here’s a nuance most books skip: the type of automation you choose shapes how you build and refactor code.
-
Over-index on unit tests, and you’ll feel a drag every time you touch the internals. Even if the behavior hasn’t changed, implementation-focused tests break and force tedious rewrites – this often delays or even prevents refactoring.
-
Lean into integration tests, and you get behavioral validation at the service boundary. As long as the contract holds, you’re free to rework the guts without rewriting half your test suite.
The smartest teams I’ve seen mix fast, isolated unit tests for critical logic and broader, integration-level tests for high-confidence behavior.
In the AI era, this is evolving again. AI-assisted tools like Keploy are making integration-level automation faster to create and maintain, removing one of the biggest historical barriers. Now, even small teams can spin up realistic, behavior-driven tests without weeks of boilerplate.
Bottom line: Test automation isn’t just “code that tests code.” It’s a design choice that influences speed, culture, and risk tolerance. And the companies doing it well are intentional about what they automate, why, and how often they revisit the strategy.
Automation vs. Manual Testing: What Senior Leaders Actually Weigh
On paper, the differences are straightforward – automation is faster, more consistent, and cheaper at scale, while manual testing is slower but better at human judgment.
In the real world, the trade-offs are more strategic.
-
Automation buys speed; manual buys insight.
Automation gives near-instant feedback but only checks what it’s told. Manual testing, especially exploratory, uncovers the edge cases scripts miss. The best teams mix both – automation for obvious risks, manual effort for the unknowns.
-
More automation ≠ faster delivery if it’s brittle.
Bloated, flaky suites slow teams down. Lean, stable automation paired with targeted manual checks often moves faster.
-
Unit-heavy strategies can backfire.
Too many implementation-dependent unit tests turn refactoring into a rewrite marathon. Modern teams favor integration-first automation that survives internal changes as long as the contract holds.
-
Manual testing is shifting left.
QA leads now collaborate early – co-designing tests, running exploratory checks on staging, and shaping automation before code hits production.
-
Automation ROI is situational with wrong tools.
High-frequency CI/CD makes automation essential. In slower or short-lived projects, the cost may outweigh the benefit if the setting up environments and feedback loop is hard.
Automation handles the repetitive, predictable, and scalable; manual testing handles the nuanced, unexpected, and high-risk. The balance point will shift as your product, team, and risk profile evolve.
Why Is Test Automation Critical Today?
Modern software isn’t just more complex – it’s more connected and more volatile. A single feature can touch dozens of services, third-party APIs, and infrastructure components. And thanks to microservices, cloud-native deployments, and AI-assisted coding, code changes happen faster than ever. What’s the benefit of test automation today?
In this environment:
-
Manual regression testing can’t keep up. Even the best QA teams can’t click through every path before each release.
-
Defects slip through earlier and spread faster. With CI/CD, broken changes can hit production within hours if there’s no automated safety net.
-
Market expectations punish slowness. Waiting days to validate changes is a competitive disadvantage when your competitors can ship multiple times a day.
High-performing teams use automation to:
-
Protect velocity – run tests (NOT JUST UNIT) on every commit, giving devs near-real-time feedback.
-
Increase coverage without increasing headcount – cover thousands of scenarios that would be impractical manually.
-
Encourage fearless refactoring – especially when integration tests validate behavior at the service level, making internal rewrites safer.
-
Shift QA earlier in the cycle – catching regressions when they’re cheapest to fix, before they hit staging or production.
In the AI era, automation also brings trust in machine-generated code. If your devs (or AI assistants) ship more code faster, you need a scalable way to validate it just as fast. That’s why AI-powered testing tools -like Keploy, co-pilot – are emerging as a core part of modern delivery pipelines, reducing the cost of writing and maintaining the most valuable tests.
Bottom line: test automation isn’t just a best practice anymore—it’s a survival skill.
The History and Evolution of Test Automation
Test automation didn’t start as a buzzword—it started as a necessity.
1970s – The First Mentions
The earliest known reference to unit testing comes from Panzl’s paper Automatic Software Test Drivers in the early ’70s, with even earlier hints buried in IBM manuals of the 1960s. Back then, “unit” was ambiguous – sometimes meaning a chunk of code, other times the smallest thing worth testing. Automation meant writing custom scripts to run specific routines, usually on mainframes, and it was rare outside of large enterprises.
1979 – “The Art of Software Testing”
Glenford Myers’ book formalized testing concepts for a wider audience. The chapter on “Module Testing” (later renamed “Module and Unit Testing” in the second edition) became a reference point. But definitions still varied, and without tooling, aut
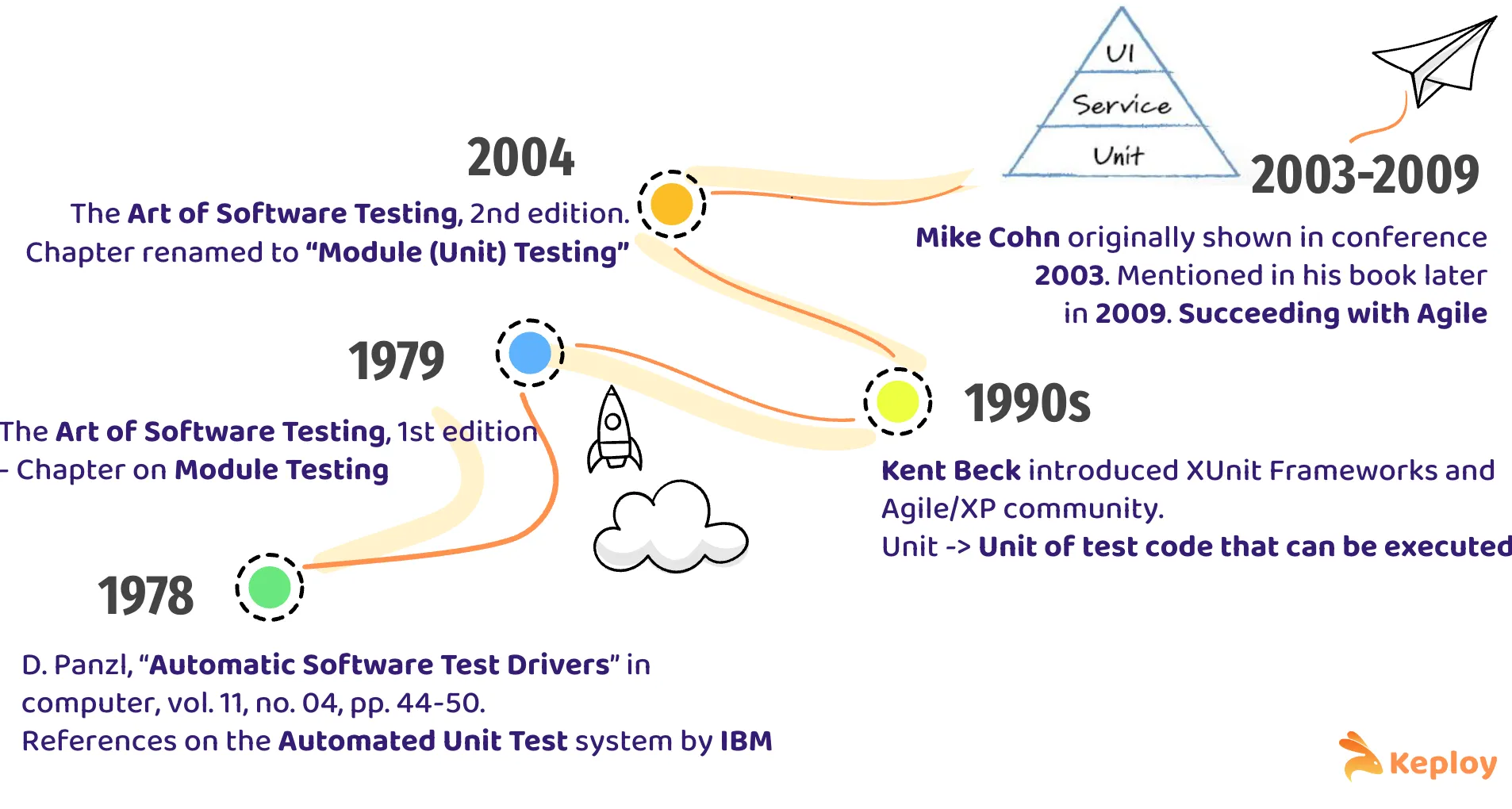
omation was far from mainstream.
1990s – Agile and Unit Test Frameworks
The rise of Agile and Extreme Programming (led by Kent Beck) popularized unit testing frameworks like JUnit. This was the first time automated tests became part of a developer’s daily life. But the focus was heavily on solitary unit tests, which tested small slices of code in isolation – fast, but brittle when internals changed.
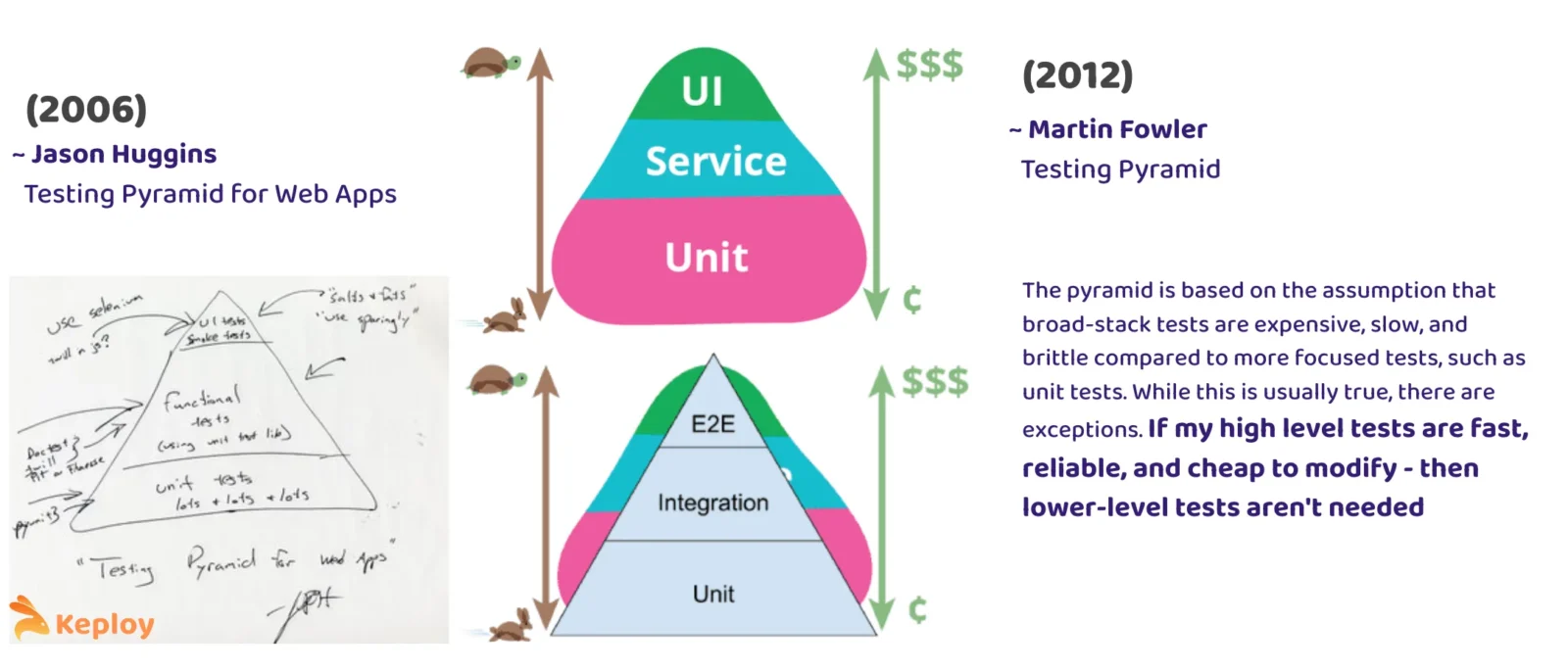
2003 – The Testing Pyramid Appears
Mike Cohn introduced the Testing Pyramid at a conference, later detailed in Succeeding with Agile. Martin Fowler amplified it: broad-stack tests are slower, costlier, and more brittle than low-level tests, so keep a wide base of unit tests scripts, fewer integration tests, and even fewer end-to-end (E2E) tests. It became a guiding model for the industry.
However, even in the XP community, there was debate over what exactly constitutes a “unit.” Some argued a unit test should test one module in complete isolation, while others were comfortable if a unit test exercised a couple of real modules together (as long as it was written by developers and run fast). This gave rise to different styles of unit testing: solitary vs sociable unit tests. Martin Fowler later used these terms (coined by Jay Fields) to describe the distinction.
-
Solitary unit tests: test a unit of code in isolation, with all collaborators or dependencies replaced by stubs or mocks. The focus is strictly on the logic within one class or function (this is often what people think of as a “pure” unit test).
-
Sociable unit tests: test a unit of code along with its real collaborators, allowing a few units to interact naturally. The test might create several objects and exercise their interactions (some argue these are more integration-like).
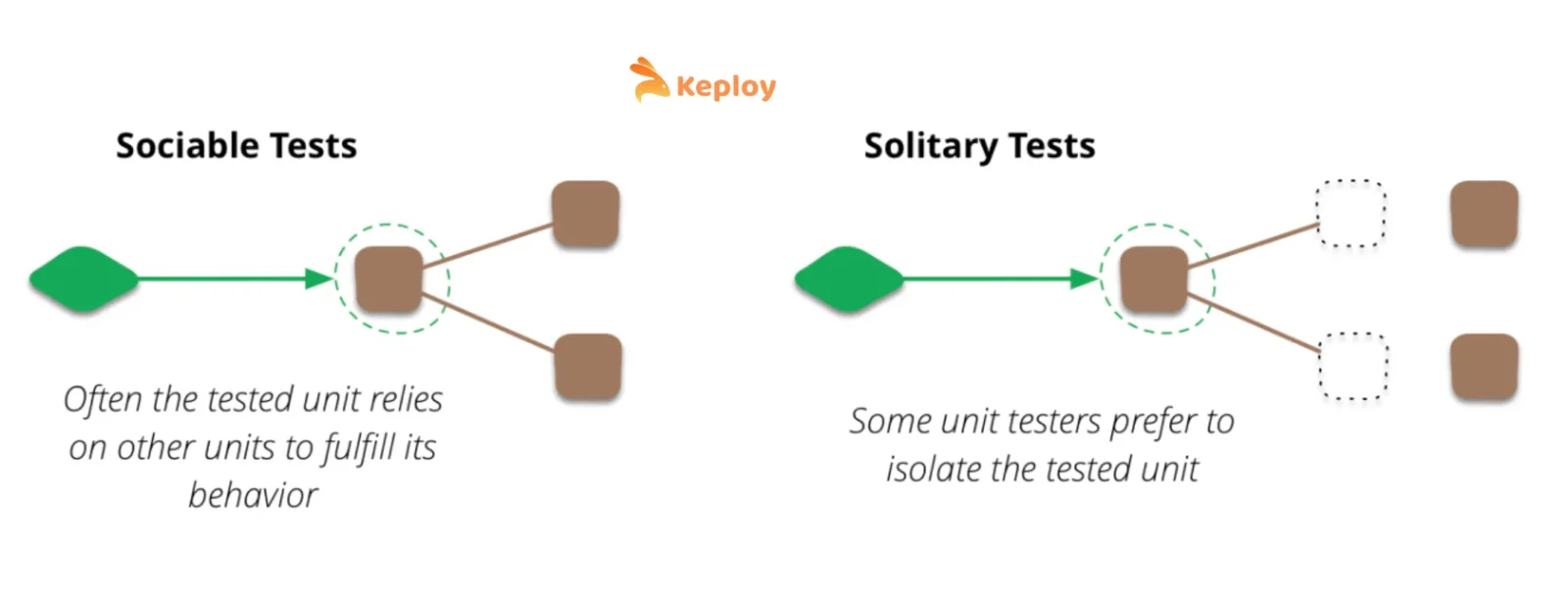
Both approaches yield small, fast tests, but the style differs. This nuanced view existed in the ’90s agile circles, but the broader industry was about to get a simpler guiding metaphor…
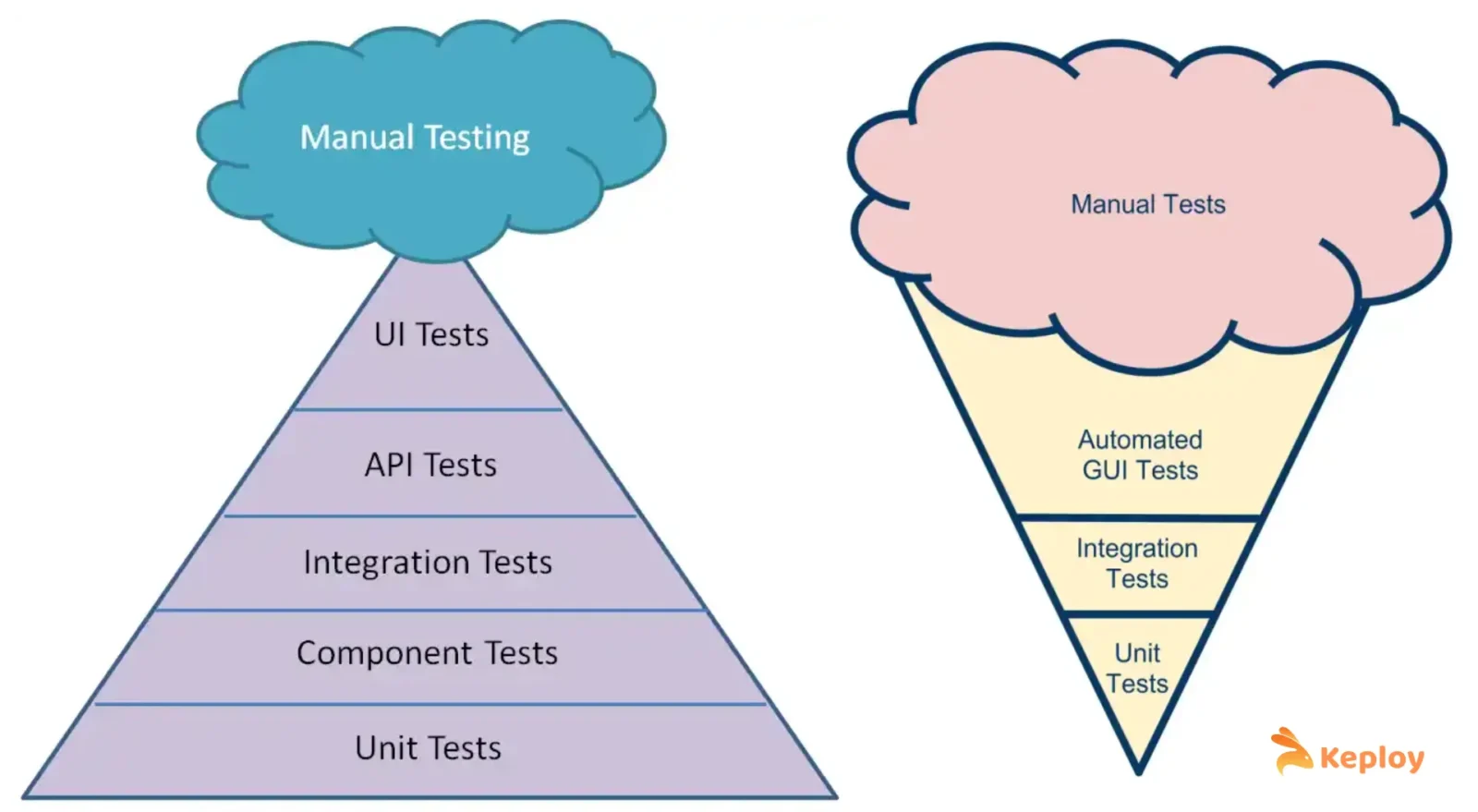
The “Ice Cream Cone” Anti-Pattern (Inverted Pyramid) – this happens in 2025 too!!
TLDR; By the mid-2000s, many teams had inverted pyramids—few unit tests, lots of slow, flaky UI tests. This often happened when devs didn’t write tests early, leaving QA to catch up with E2E scripts. The result: slow feedback, higher costs, and a brittle suite that teams feared to run.
Not all organizations successfully implemented the pyramid. Some fell into the trap of doing the exact opposite – a few unit tests at the bottom and an avalanche of manual or UI tests on top. This inverted pyramid is often called the “Ice Cream Cone” anti-pattern (imagine an ice cream cone: a tiny pointed bottom and a big scoop on top). In an ice-cream cone testing structure, the majority of testing relies on manual tests or slow end-to-end tests, with very little automation at the unit level.
Why does this happen? One reason is cultural: if developers are not encouraged or trained to write unit tests early and often, then the responsibility for testing falls mostly to a separate QA team. Those testers, not having unit-level hooks into the code, end up creating more UI-level automated tests scripts or doing more manual testing to cover the gaps. During the early Agile/DevOps transitions, many large organizations still kept a divide between developers and testers – with testers often not having full access to the codebase. Without unit tests written by developers, the test suite gets “top-heavy” with higher-level tests to compensate.
Another reason is pressure from management or stakeholders to demonstrate working features quickly. They might push for visible end-to-end tests (or manual demos) that show the whole system working, to get confidence in the software. This can lead teams to prioritize system tests while neglecting the lower layers. It’s a shortsighted approach: while a passing end-to-end test might impress a stakeholder in a demo, the lack of lower-level coverage means regressions can slip in undetected until they break something big.
Over time, the ice-cream cone approach proves inefficient and unsustainable. Manual testing effort grows linearly (or worse) with each new feature. Test cycles become longer and longer, slowing down releases. QA teams start drowning in regression tests, or they have to cut corners (increasing risk). Automated UI tests, if too many, create a maintenance nightmare: they are brittle with frequent UI changes, and diagnosing their failures can be time-consuming.
Testing thought leaders have strongly cautioned against the ice cream cone pattern. Martin Fowler noted that relying mostly on end-to-end GUI tests leads to slow, brittle suites – often requiring expensive GUI automation tools and special test environments, and yielding non-deterministic results that undermine trust in tests. In a colorful analogy, one commentator described heavy manual testing at the top as causing a “melting ice cream” effect – as manual testing effort melts (fails to scale), it drips down and creates a mess in other layers (meaning defects leak through, and more pressure is put on every part of the process).
Avoiding the Ice Cream Cone: The cure is essentially to invert the investment – build up the base of the pyramid. That means fostering a culture where developers write unit tests and maybe service-level tests as part of development. It also means educating non-technical stakeholders that a green UI test is not the only indicator of quality; a solid foundation of unit tests provides invisible but crucial stability. Many teams that successfully moved away from the ice-cream cone did so by introducing requirements like code coverage targets for unit tests, pairing QA with devs to write API-level tests, and automating what used to be manual checks at lower levels. It can be a challenging transition, but it pays off in vastly reduced regression costs.
2010s – Rethinking the Shapes
As microservices and distributed systems grew, the Pyramid started to crack under real-world complexity. Industry thought leaders proposed new models:
Honeycomb (Spotify’s Model, 2018)
TLDR; Focus on integration tests over unit tests, because they validate service boundaries without breaking on internal refactors. Avoid “integrated tests” that rely on other systems.
-
In the Honeycomb model (visualized as a hexagon shape), the focus is on Integration tests – the middle of the honeycomb is big. The top of the honeycomb represents very few “Integrated” tests (end-to-end tests), ideally none. The bottom represents a few “Implementation Detail” tests, which correspond to unit tests of internal code if needed. In other words, Spotify suggested: write mostly integration tests, have a handful of unit tests for complex internal logic, and avoid broad end-to-end tests that depend on other services if you can.
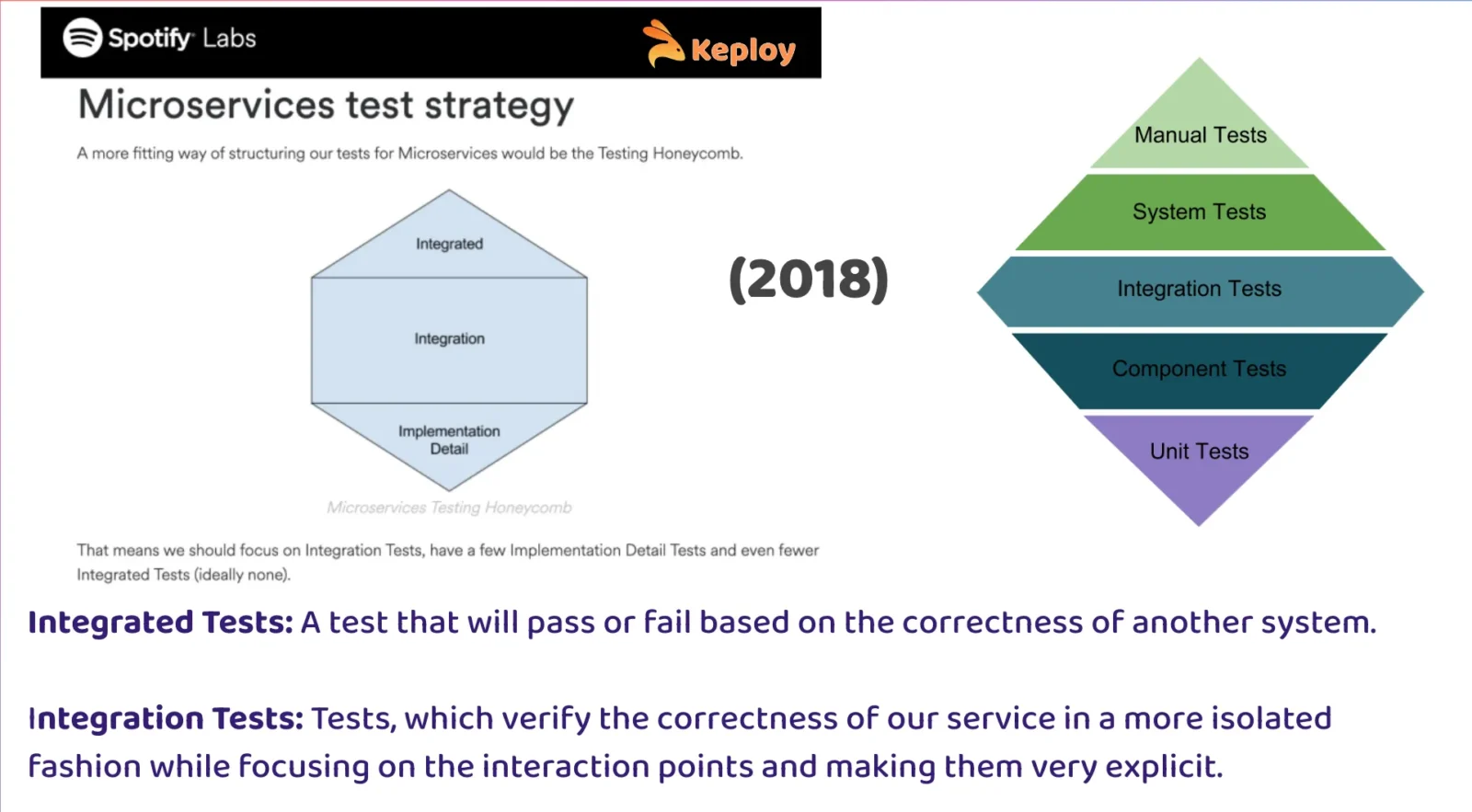
But what exactly do they mean by Integration vs. Integrated? Spotify drew a crucial distinction (based on J.B. Rainsberger’s talk “Integrated Tests Are a Scam”):
-
An Integrated Test is one that will pass or fail based on the correctness of another system. In other words, it exercises not only your service but also actual external services or databases – if those external components have bugs or are unavailable, the test fails. Signs of integrated tests include: spinning up multiple services together in a test environment, testing against a shared staging environment, or seeing tests for System A failing because System B changed. These tests are brittle and slow by nature, because they involve multiple moving parts and environments.
-
An Integration Test (in Spotify’s lingo) is a test of your service in isolation, focusing on how it integrates with others by stubbing or simulating the other systems. For example, to test Service A’s integration with a database or another service, you might spin up Service A with an in-memory fake database, or stub out calls to Service B with predefined responses. The test verifies that Service A produces the expected outcomes when the integration points behave as expected. Essentially, it’s like a high-level test of Service A, but controlling the interaction points.
Spotify’s approach was to avoid integrated tests entirely (hence the top of the honeycomb ideally having none) because they found them “fragile” and hard to maintain. Instead, they wrote robust integration tests with simulated dependencies. For example, if Service A depends on a SQL database and provides a REST API, an integration test would: start a local instance of the DB (or use an in-memory variant), deploy Service A (maybe in a container or local process), then hit Service A’s REST API and verify responses. This test covers a lot – it’s almost end-to-end for Service A, but it doesn’t require other services or a production-like environment. It’s all self-contained.
As a result, the test is slower than a pure unit test (since it starts a DB and the service), but still much faster and more reliable than a full multi-service integration test. Spotify reported that even for a simple service, they might have zero unit tests and just integration tests that spin up the service with a test DB, because that gave them full confidence with very few tests. They could refactor the internal code freely (even swap out PostgreSQL for a NoSQL store) without changing test logic – only the setup might change if an integration point changes.
They acknowledged a trade-off: these integration tests run in seconds rather than milliseconds, so you lose some speed, but you gain far more in realistic coverage and reduced maintenance. In complex services, integration tests allow verifying real interactions (publishing messages, receiving outputs) in a black-box fashion, which can often cover scenarios that would require dozens of isolated unit tests to check in pieces engineering. If a test fails, you might have to dig through the service’s stack trace to find the bug, but Spotify felt this was acceptable given the benefits.
They still see a place for Implementation-Detail (Unit) Tests – but use them sparingly for things like complicated algorithms or logic that is easier to test in isolation. For example, Spotify had a complicated log file parser in their CI system. They wrote unit tests to cover every parsing scenario, rather than writing an integration test for each log variation (which would be slow). But this was the exception, not the rule.
The Testing Honeycomb thus flips the traditional pyramid for microservices: it advocates investing heavily in integration tests (with controlled interactions), having few unit tests, and minimizing cross-system tests. It reflects a reality that in microservices, the “unit” of deployment (and failure) is often the service, not a tiny function. And because services interact over networks and through APIs, testing those interactions thoroughly is key. By isolating each service in tests (with mocks/doubles for others), you decouple test failures and make the suite more reliable, while still exercising realistic usage patterns.
One visual addition Spotify made was drawing a little cloud symbol above the honeycomb to represent manual testing happening outside of automation. This indicates that manual exploratory testing is not part of the automated layers but exists as an additional check when needed (e.g. exploratory testing can be done on any layer, but it’s not depicted as a layer in the automation pyramid/honeycomb).
-
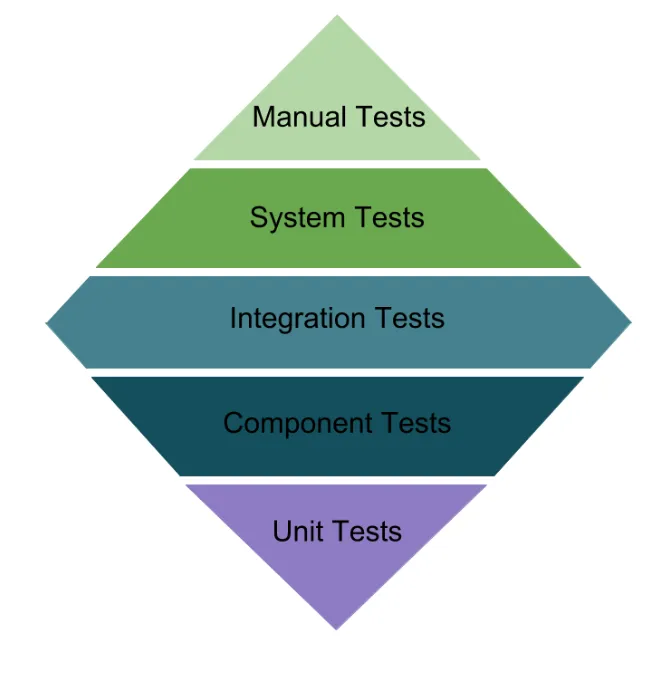
Testing Diamond
TLDR; Emphasizes the growing importance of service-layer testing in modern architectures.
Other organizations have proposed similar tweaks. Some refer to a “Testing Diamond” – which, like the honeycomb, has a wider integration layer and relatively fewer unit tests (so shape-wise, it’s like a diamond with integration in the middle as the widest part). The exact terminology varies, but the trend is born from the same observation: if lower-level unit tests are hard to maintain or provide little ROI, and if you can make integration tests fast and stable, then it’s okay to have fewer unit tests than traditionally prescribed. The end goal is still confidence in the software, with the least painful maintenance burden.
Testing Trophy (Kent C. Dodds)
TLDR; Keep integration tests central, with static analysis and unit tests as supporting layers. Add “external tests” for things you can’t fully control (third-party APIs, SaaS dependencies).
One proponent of this view, Kent C. Dodds, famously tweeted: “Write tests. Not too many. Mostly integration.” – distilling the idea that you shouldn’t aim for 100% unit test coverage if integration tests give you more bang for your buck. He introduced the Testing Trophy model as a more integration-focused alternative.
The Testing Trophy was proposed by Kent C. Dodds around 2018 as he reflected on the types of tests that gave him the best return on investment (particularly in web application development). The trophy is like a cup with a base, stem, and a broad top – representing (from bottom to top): Static tests, Unit tests, Integration tests, End-to-End tests. The largest area in the trophy (the cup part) is integration tests, indicating he favors a lot of integration testing. There’s a thin stem for unit tests (some, but not overly many), and a small top for a few e2e tests. The base is static analysis.
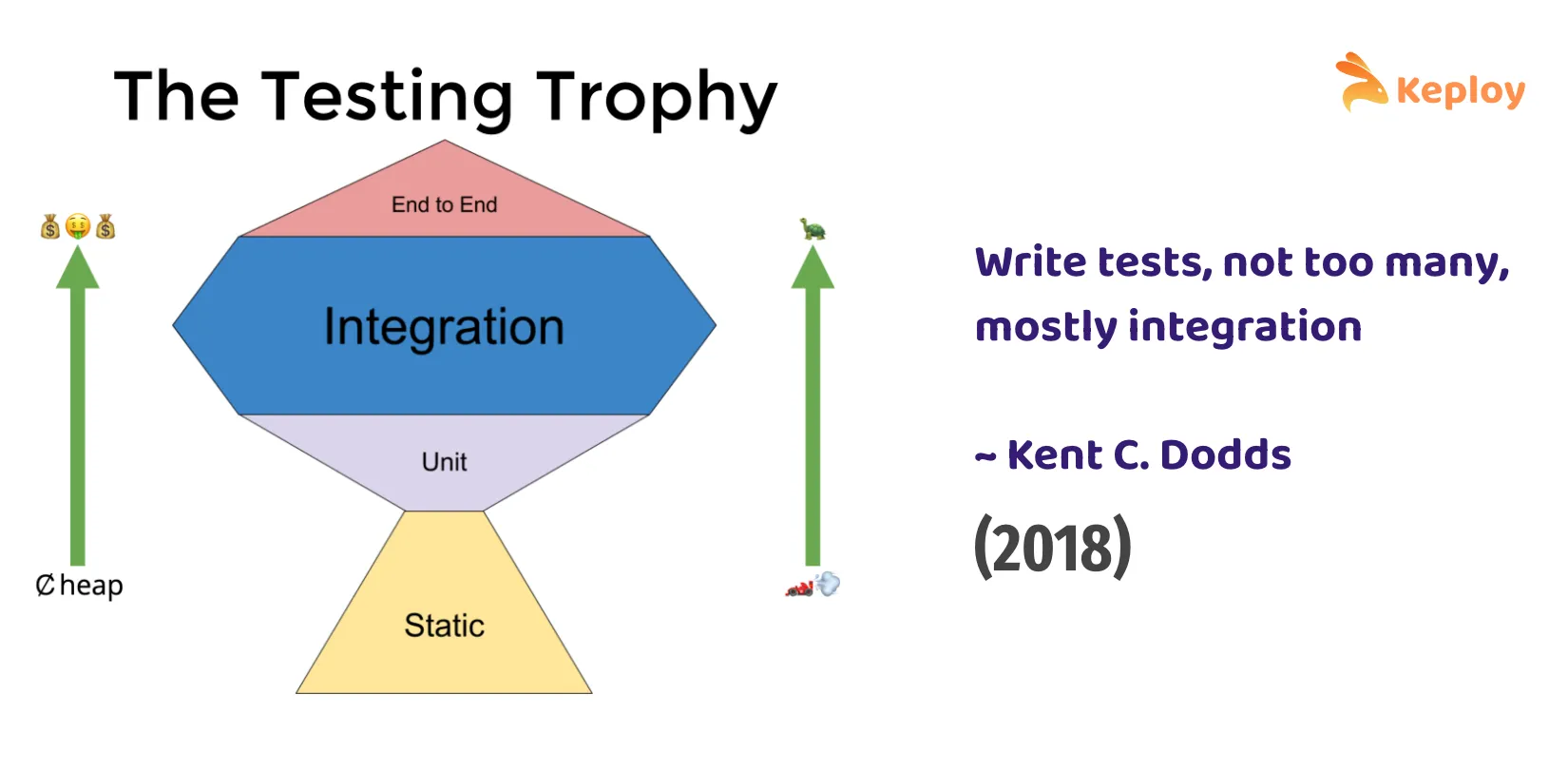
Here’s the breakdown:
-
Static Testing (base): This refers to things like type checking (e.g., TypeScript, Flow) and linting, which aren’t traditionally considered “tests” in the same sense but are automated checks on the code. Dodds includes static analysis as foundational because in languages like JavaScript, adding a static type checker can catch an entire class of errors (typos, type mismatches) before tests even run. Static analysis is fast, runs on save or compile, and prevents silly mistakes, thereby reducing what you need to test at runtime.
-
Unit Tests (small section above base): Dodds defines unit tests in a somewhat stricter way – tests that verify a single “unit” in isolation (with dependencies mocked out). These are similar to Fowler’s “solitary” unit tests. You write them for pure functions or components where you can isolate behavior. Dodds acknowledges unit tests are valuable especially for utility functions or complex pure logic, but he warns against overusing mocks in unit tests for behavior that could be tested more realistically with integration tests.
-
Integration Tests (large section, the trophy bowl): He uses integration test to mean tests that exercise multiple components of the system together, preferably in a way close to how the end user would – but still within the app’s context (not a full end-to-end with external systems). For a web app, a typical integration test might render a page or component with a real web UI framework, but mock out network requests or use a test database, and then simulate user actions (clicks, inputs) to verify things work. These tests cover multiple units integrated, often without mocking the internal interactions (so they are more “sociable”). Dodds found these tests gave him the most confidence because they catch issues with how units work together, which is where many bugs occur.
-
End-to-End (E2E) Tests (small top): These are full-stack tests with as little mocking as possible – essentially treating the application as a black box and testing it like a user would, clicking through UI and even hitting real APIs or a staging environment. They provide the highest confidence (because everything is real) but they are slow and can be flaky. So, as with the pyramid, the trophy suggests keeping E2E tests to a small, important subset (critical user paths, high-risk scenarios).
One novel addition of the trophy is explicitly calling out static testing. In classical pyramid discussions, people often forgot that things like linters or code analyzers can catch bugs before any dynamic test runs. Including it in the trophy highlights that a comprehensive testing strategy starts even before running the program.
Kent Dodds arrived at this model based on his experience that “not all tests give equal value.” Some unit tests, especially those that heavily mock out collaborators, can end up verifying the implementation rather than the true functionality – leading to brittle tests that need rewrites whenever you refactor (but don’t actually catch higher-level issues). On the other hand, writing too many end-to-end tests slows down the feedback loop and increases maintenance. Integration tests, in the middle, often hit the sweet spot: they test multiple units together so you know the pieces talk to each other properly, yet they run faster and are easier to debug than full E2E tests.
An example scenario: Suppose you have a React UI that talks to an API and then updates some state which triggers another component. A unit test might test the component’s internal state logic with mocks for the API calls. An integration test might spin up a test version of the API (or mock at the network boundary), render the actual UI components in a headless browser environment, perform a user action, and observe that all components update correctly. This integration test would catch if, say, two components didn’t integrate correctly (perhaps a context or props issue), which a solitary unit test might miss because the units were tested in isolation. Yet it would run faster than an end-to-end test that might require deploying a test server, because it could use a local simulation of the API.
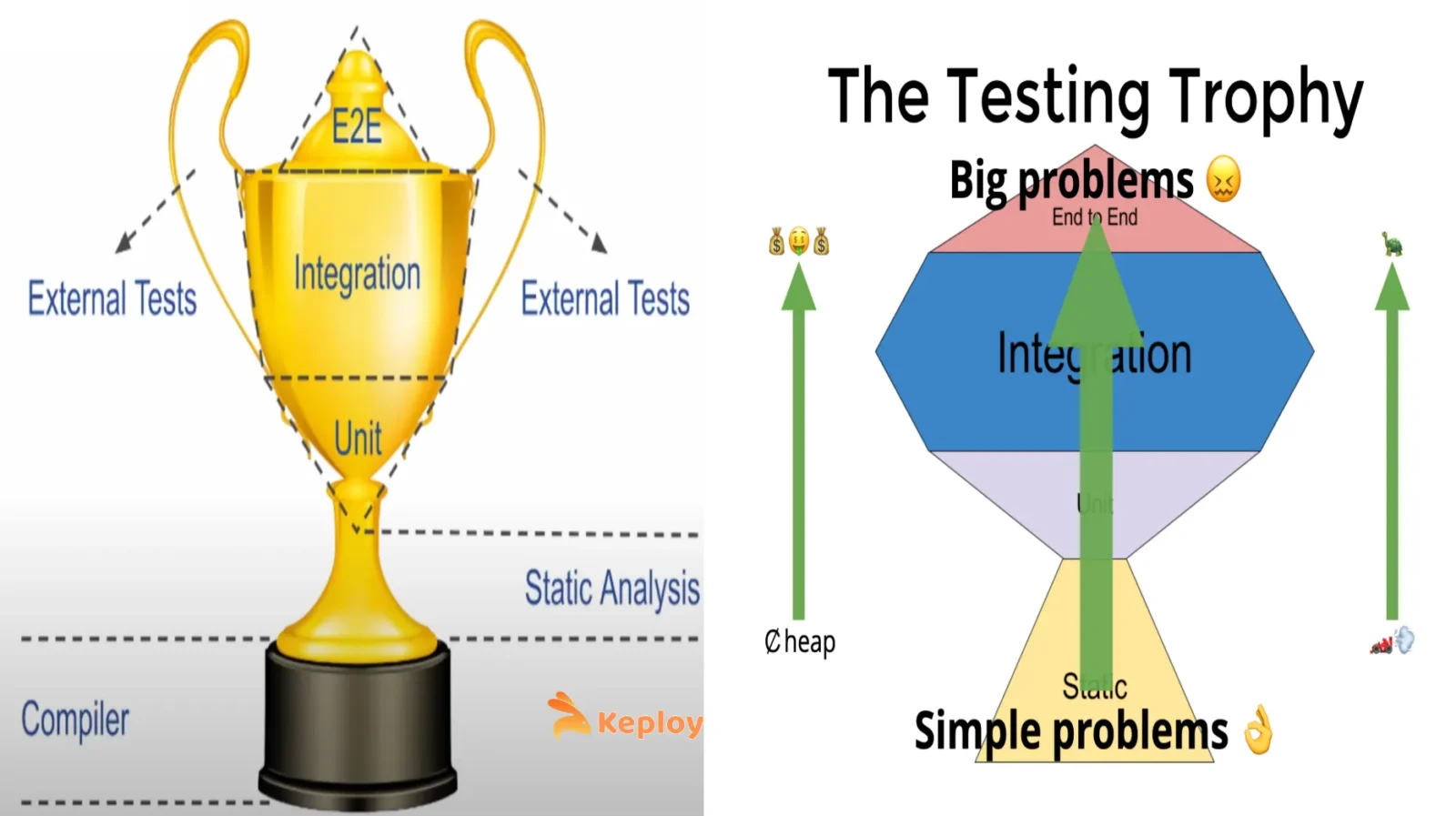
Dodds is careful to note that definitions of “unit” and “integration” vary (he humorously points out there are dozens of definitions of unit test, echoing the earlier discussion). His intent was to choose definitions that made sense for his context (mostly JavaScript web apps) and maximize confidence with minimal tests. He emphasizes writing tests that resemble how the software is used, which naturally pushes toward integration tests over overly isolated ones. A famous quote he shares is: “The more your tests resemble the way your software is used, the more confidence they can give you.” – which is why he discourages tests that, for example, shallow-render a React component and assert on internal state (nobody uses your app by calling your component’s internal methods – they use it by clicking on it in a browser).
Some engineers at VMware later extended the trophy concept by adding a “handle” to the trophy – representing external tests beyond the control of the team (like tests performed by external systems or in production). This acknowledges that in complex environments, there are always some tests (like third-party integration tests, compliance tests, etc.) that don’t fit neatly in the trophy but you must account for them. They also layered in the idea of confidence vs. effort – lower-level tests are easier to write but give narrower confidence, whereas higher-level tests are harder to write but validate broader behavior, hence you need a mix. This is essentially a restatement of the pyramid’s classic trade-off (small vs. big tests), but in trophy form.
Modern Test Automation Strategy (2025–2030)
If the last two decades of testing taught us anything, it’s this: models are useful, but dogma kills velocity.
Senior engineering leaders now face a different reality than the one the Testing Pyramid was designed for. Today’s test automation strategy needs to account for microservices sprawl, AI-assisted code generation, distributed teams, and the fact that most products are never “done.”
Is the Testing Pyramid Obsolete?
With all these shapes – pyramid, cone, trophy, honeycomb, diamond – one might wonder if the original Testing Pyramid is outdated. The answer from experts is no – the pyramid’s core message is still valuable, but you must interpret it with clear definitions and appropriate context.
Martin Fowler observed in 2021 that much of the debate (“pyramid vs honeycomb vs trophy”) is muddied by inconsistent terminology. When some people say “unit test”, they mean a solitary, isolated test of one class. Others might mean any in-memory test that doesn’t hit external systems (even if it covers several classes). Likewise, “integration test” can mean a wide range of things. Fowler pointed out that many proponents of the honeycomb/trophy models were essentially advocating for more “sociable” tests (units with real collaborations) and fewer “solitary” tests (units with everything mocked). In his terms, what they call an “integration test” is very close to what he would call a sociable unit test – a test of multiple units in combination. And what they call a “unit test” is the very isolated solitary unit test with heavy use of test doubles.
If you look at it that way, the difference is often one of emphasis rather than total opposition. Fowler noted that classical descriptions of the test pyramid never explicitly said those unit tests had to be solitary or that you must use mocks extensively. The pyramid just said “lots of automated tests scripts at the unit level,” which could include sociable tests. Indeed, many teams practicing TDD write their unit tests without a lot of mocking (only isolating truly external dependencies like network or database calls), which essentially makes those tests integration tests in the broad sense. So, a team could follow the pyramid in spirit but still align with the trophy in practice by writing sociable unit tests liberally.
Fowler’s advice is to focus less on the ratios and more on writing high-quality tests that are fast, reliable, and maintainable. A quote he highlighted from Justin Searls captures this: “People love debating what percentage of which type of tests to write, but it’s a distraction. Nearly zero teams write expressive tests that establish clear boundaries, run quickly & reliably, and only fail for useful reasons. Focus on that instead”. In other words, it’s more important to have tests that give you confidence (by being well-designed and trustworthy) than to bike-shed over the exact shape of your test distribution.
That said, the Pyramid model remains a good starting point for many projects. For a typical information system (e.g., a web app with a database), the advice of lots of fast unit tests, some API tests, and a few end-to-end scenarios is usually sound. The newer models simply remind us to not be dogmatic. If your project finds, for instance, that maintaining 1000 unit tests that assert every minor detail is a burden and that 200 broader tests could cover the same critical paths more effectively, it’s okay to shift the balance.
The Testing Pyramid is not obsolete, but it is not a one-size-fits-all mandate. Think of it as a heuristic: if you find yourself with very few unit tests and tons of slow manual tests (inverted pyramid), that’s a red flag – you likely need more automation at lower levels. If you find yourself with 100% unit-test coverage but still missing obvious integration bugs, maybe you overdid the bottom and need more middle. The ultimate goal is risk-driven testing: invest test effort where the risk of bugs is highest and where automation can best mitigate that risk.
As Fowler noted, debating whether the pyramid should be replaced by a trophy or honeycomb might be missing the point. All these models agree on a fundamental idea: tests at different levels have different costs and benefits, and you should have a mix of them. The exact mix should be determined by your system’s context (e.g., microservices favoring integration tests) and by where you can get the most confidence for the least pain.
In practice, many teams today take a hybrid approach:
-
They use the pyramid as a general guideline (don’t rely solely on slow UI tests; be sure to include fast checks).
-
They incorporate trophy/honeycomb ideas by making heavy use of API-level tests and not worrying if those outnumber the pure unit tests.
-
They ensure some end-to-end tests exist for critical journeys, but they don’t go overboard and try to test every permutation via the UI.
-
They include static analysis (linters, type checkers, security scans) as part of the automated quality gates.
This pragmatic approach yields a test suite that is fast, gives good coverage, and still keeps maintenance manageable. Now that we’ve covered the evolution of testing strategies, let’s shift to how to actually implement a successful test automation strategy on a team.
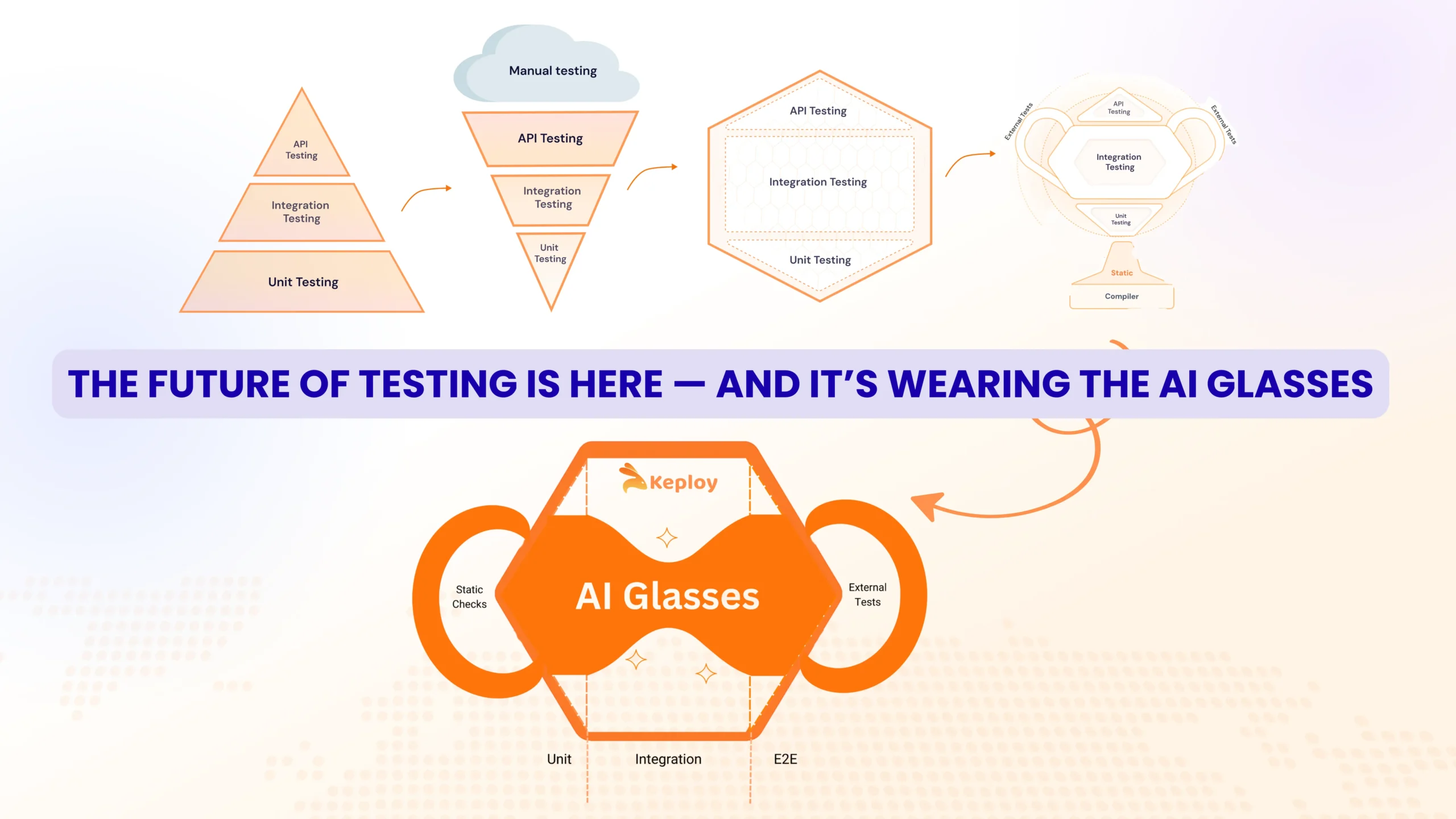
The New Testing Pyramid: AI Glasses Model
The AI Glasses Model is my evolution of the traditional Testing Pyramid, Trophy, and Honeycomb ideas for the AI era. It’s designed to reflect how AI can actively participate in your testing strategy — not just as a helper, but as an embedded layer that takes on the bulk of repetitive work.
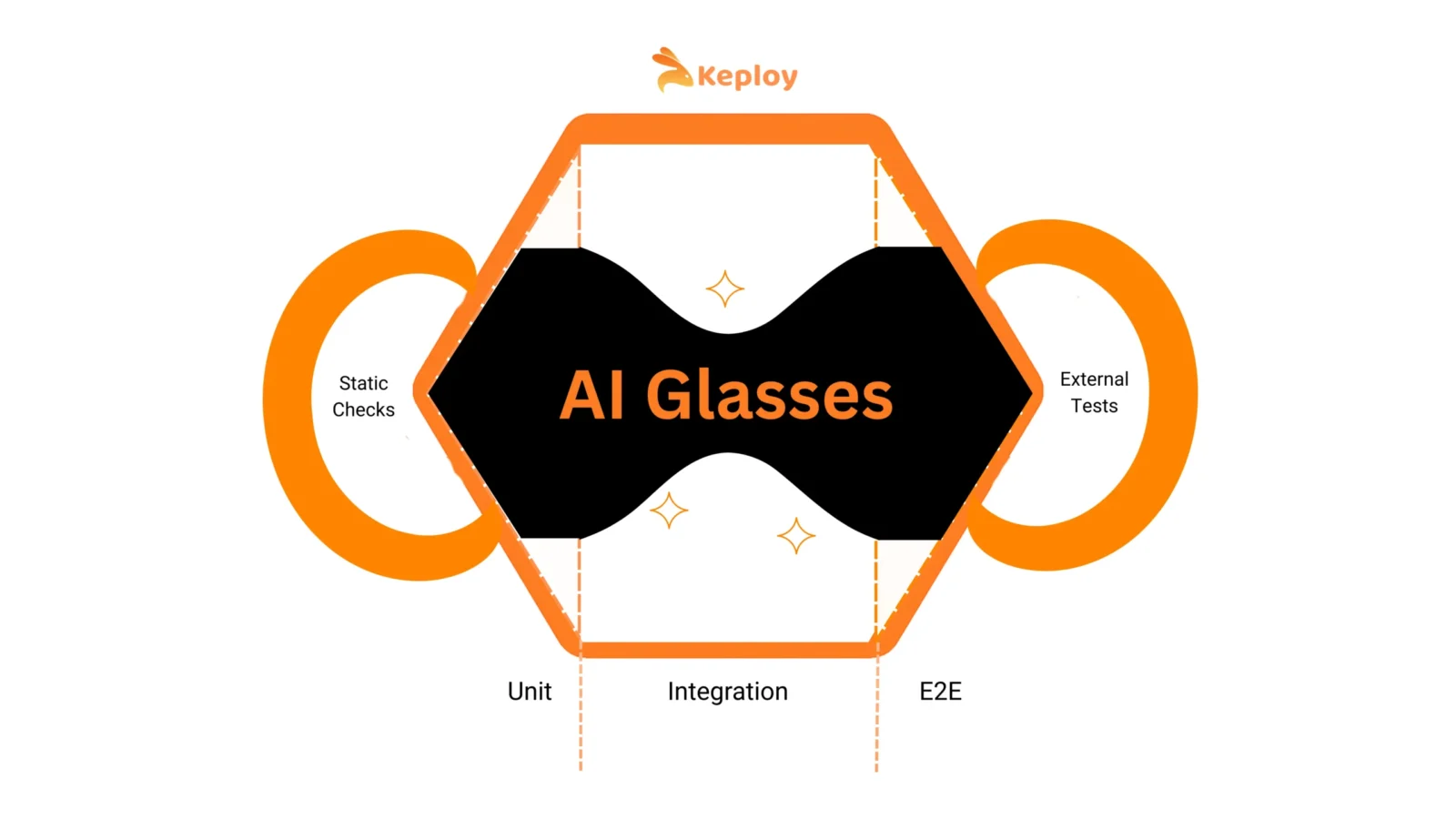
A horizontal honeycomb “face,” with three layers – Unit, Integration, E2E — and two “ears” for Static Checks (left of SDLC) and External Tests (right of SDLC).
Through it runs an hourglass-shaped AI layer that:
-
Automates 100% of Static Checks — linting, type safety, security scans
-
Covers most Unit & E2E tests via AI-generated, self-healing automation. Today,
-
Unit: 70–80% good coverage achievable with AI agents
-
API/E2E: 80–90% schema coverage possible with test-agents like
Keploy
-
Partially covers Integration tests — the most complex & context-heavy layer. AI agents are less deterministic here, but Keploy.io solves this by observing real traffic and deterministically replaying scenarios, including stress & fuzz testing for edge cases.
It’s not replacing humans — it’s redefining where they spend effort.
AI handles repetitive, automatable layers; humans focus on high-context, high-risk, high-value testing that can’t be automated. This structure makes it easy to see that AI is not replacing every testing activity — instead, it’s strategically covering the most automatable layers and amplifying human effort where creativity and context are essential.
In practice, teams using this model can:
-
Accelerate feedback loops without bloating test suites.
-
Keep maintenance manageable through self-healing, AI-generated tests.
-
Focus manual energy on integration complexity and exploratory validation.
The AI Glasses Model doesn’t replace the Pyramid or Trophy — it “sits on top” of them, giving engineering teams a clear, visual way to decide where AI should work for them, and where humans should remain in the loop.
Building a Successful Test Automation Strategy
The AI Era – Automation is at Scale
Now, code changes happen faster thanks to AI-assisted development. That speed widens the gap between “what we can test manually” and “what we must guarantee before shipping.” Teams are leaning heavily on integration-first automation because:
-
It supports fearless refactoring—tests survive internal code changes.
-
It gives higher real-world confidence than unit-heavy strategies.
-
AI-assisted tools like Keploy can generate and maintain integration tests in hours, lowering the historical cost barrier.
Key Lesson: The models (Pyramid, Honeycomb, Trophy) aren’t competing—they’re lenses. The right mix depends on your architecture, team maturity, and risk profile. The biggest mistake is treating any shape as north star instead of adapting it to reality.

Here’s what’s working for the best teams right now:
1. Integration-First, Not Unit-First
Unit tests are still valuable for core logic, but over-indexing on them slows down refactoring and bloats maintenance costs. Integration tests—targeting service or API boundaries—offer high confidence while staying resilient to internal code changes.
AI-assisted integration test generation is making this approach accessible even for small teams that couldn’t previously afford the setup cost.
2. Strategic End-to-End Coverage
E2E tests are expensive and slow, but they deliver the highest confidence for business-critical flows. Modern teams keep these lean and laser-focused—covering only the “money paths” (e.g., signup → checkout → payment).
3. Automate for Risk, Not for Metrics
Test coverage percentage is a vanity metric. Leading teams map automation priorities to business risk—critical revenue paths, security boundaries, and compliance-sensitive flows get automated first. Low-risk, rarely-touched code may remain manual.
4. Embed Testing in Dev Workflows
Testing isn’t a phase—it’s an always-on process. The best teams run automated tests scripts on every PR, block merges on failures, and pair devs with QA early to design both automated and manual checks.
5. Treat Test Maintenance as a First-Class Activity
Flaky, outdated, or redundant tests destroy trust in automation. Top teams schedule regular “test debt” sprints, prune dead tests, and refactor slow ones.
AI tooling like Co-Pilot, Keploy, Postman is also helping here—self-healing tests that adapt to schema changes cut maintenance time drastically.
6. Leverage AI for Scale and Complexity
With AI writing more code, automation must scale proportionally. AI-driven testing tools are moving from “nice to have” to “non-negotiable,” generating test suites from real traffic data, contracts, and code diffs.
7. Balance Automation with Exploratory Testing
Automation handles the known risks; exploratory testing finds the unknown ones. High-performing teams budget dedicated cycles for exploratory work, guided by recent production incidents and product changes.
Bottom line:
A modern test automation strategy isn’t about following a pyramid, honeycomb, or trophy. It’s about engineering confidence at speed—aligning test investments with business risk, architectural reality, and the velocity your market demands.
Feeling Overwhelmed? Decide What Will Works For You??
Having the right mix of tests is one part of the puzzle; the other part is how you implement and manage test automation in your development process. A solid strategy includes deciding what to automate, how to design your tests for longevity, and which tools and frameworks to use. It also involves setting up the necessary infrastructure (environments, CI/CD integration) and defining processes for test automation maintenance and monitoring your tests.
Here are some key components and steps for effective test automation in practice:
Define What to Automate (and What Not To)
Not every test should be automated. Begin by identifying high-value candidates for automation:
-
Repetitive Tests: Tests that need to be run repeatedly for each build or release (e.g., regression tests that verify existing functionality hasn’t broken). These are prime targets because doing them manually each time is tedious and error-prone.
-
Tests with Large Data Combinations: For example, form validations with many input variations, or algorithm correctness over many test vectors. Automation can cycle through numerous data sets far faster than a human.
-
Objective Verification Steps: Scenarios where expected results are well-defined (e.g., “For input X, output should be Y”). These lend themselves to automation. By contrast, tests that require subjective judgment (like “is this UI aesthetically pleasing?”) are not automatable.
-
Performance and Load Tests: These often involve simulating thousands of users or high transaction volumes – tasks impossible to do manually. Automate these with appropriate tools.
-
Cross-Environment Tests: If you need to test on various browsers, OSes, or device types, automation through a tool or cloud service can run the same script on all platforms, ensuring consistency.
On the flip side, decide what not to automate:
-
Exploratory and Ad-hoc Testing: The creative, unscripted testing aimed at discovering unknown issues (UI oddities, usability problems, etc.) is best done manually by skilled testers.
-
One-off or Short-Lived Features: If something is experimental or will be replaced soon, heavy automation might not pay off.
-
Areas with Frequent UI Changes: If the UI design is in flux, UI automation can become a time sink due to constant updates. In such cases, focus on automating at an API or unit level until the UI stabilizes, or use more resilient automation techniques (like AI-based locators).
By being selective, you ensure that the effort spent on automation yields maximum returns in saved time and increased confidence.
Choose the Right Tools and Frameworks (AI Era)
Picking the right tools isn’t about checking boxes—it’s about fitting the stack to your architecture, velocity goals, and team skill set. In the AI era, that also means choosing tools that can adapt, self-heal, and integrate with intelligent pipelines.
-
Unit Testing – Still foundational for critical logic. Most languages ship with mature frameworks (JUnit/TestNG for Java, pytest/unittest for Python, NUnit for .NET). But AI-assisted code generation with tools like Co-pilot, Chatgpt, Claude, etc.. means more code changes, so keep unit tests focused and high-value to avoid a brittle suite.
-
API Testing – With microservices, APIs are where most business logic lives. Use developer-friendly libraries (REST Assured, Keploy) for scripted testing, or Postman for quick design/debug cycles. AI-powered tools like Keploy now auto-generate API, Integration and contract tests directly from real traffic, making it easier to maintain behavioral coverage.
- UI Testing – Modern frameworks like Playwright and Cypress offer faster, more reliable browser automation than legacy Selenium. They also integrate with AI-driven self-healing locators (e.g., Testim, Applitools) to reduce maintenance. Appium remains a go-to for mobile. Keep UI tests lean—cover only the highest-value flows.
- BDD & Acceptance – Cucumber, Keploy still help align product, QA, and dev, but AI is making Gherkin-to-code generation more seamless, letting non-devs contribute executable scenarios without bottlenecking engineers. We use Keploy to record and replay the BDD tests from the API calls and mocking the infra.
- Performance & Load – Tools like JMeter, Gatling, Keploy and Locust remain relevant, but are now often paired with AI analytics to spot performance regressions early and correlate them with code changes.
- Continuous Integration (CI/CD) – Jenkins, GitHub Actions, GitLab CI, Azure DevOps are the execution backbone. In the AI era, these pipelines also orchestrate AI-driven test selection—running only the most relevant subset per commit for faster feedback.
-
Service Virtualization & Mocking – WireMock, Mountebank are still staples, but AI-assisted mock generation using Keploy has changed the way mocking is done today. Means you can create realistic stubs directly from production traces, ensuring integration tests run without external fragility.
-
Test Data Management – Faker, Mockaroo, Keploy and other generators now integrate with AI to produce edge-case data automatically, increasing defect detection without manual dataset crafting.
- Reporting & Analytics – Dashboards like Codecov, Keploy, and custom CI reports are moving beyond pass/fail, surfacing patterns in flaky tests, failure clustering, and test debt—often powered by ML.
- Codeless & Low-Code – Tools like Tricentis Tosca, testRigor, and Keploy are evolving with AI-based self-healing and natural-language-to-test features. They work well for rapid prototyping or enabling non-technical testers. So prepare well for codeless test automation.
- AI-Powered Testing – Beyond visual AI from Playwright, the new frontier is AI creating, running, and maintaining tests from real-world signals. Keploy, for example, generates integration and API tests from production traffic and keeps them up-to-date as contracts change—bridging the historical gap between speed and coverage.
Key Takeaway: In 2030, the “best” tool isn’t just the one with the richest feature set—it’s the one that can keep up with your codebase without turning your QA team into full-time test maintainers. AI-first tools are becoming essential to make that possible.
Establish a Robust Automation Framework
Beyond individual tools, think of your automation framework as the glue and structure of your tests. This includes how you organize test code, handle configurations, manage test data, and so on. Some best practices:
· Standardize the Project Structure: Keep your test code in a separate but parallel structure to application code. For example, have a tests directory with subdirectories for unit, integration, e2e, etc. Use clear naming conventions. This makes it easy for anyone in the team to find and run tests.
· Use a Base Test Class or Utility Functions: For common setup/teardown tasks (e.g., initializing a database with test data, or launching a browser and logging in), factor that into reusable functions or base classes. This avoids duplicating boilerplate in every test and ensures consistency.
· Parameterization and Data-Driven Testing: Use your framework’s features to run the same test logic with multiple inputs. For instance, JUnit and pytest allow parameterized tests. This avoids writing one test per data combo; instead the test framework will iterate inputs. It’s great for covering many cases in a compact way.
· Isolate Test Environments: Especially for integration and E2E tests, have a dedicated test environment or use containers to bring up ephemeral environments. The goal is that tests run on known data and won’t conflict with each other or with dev/production data. Tools like Docker and Docker Compose are frequently used to spin up services (e.g., a test database) during test runs, then tear them down.
· Continuous Integration & Pipeline Integration: Ensure that running the tests is part of your normal build process. For example, developers can run unit tests locally with a simple command, and the CI server runs them on each push. Integration/E2E tests might run on a nightly schedule or on merges to a main branch if they are too slow for every commit. The pipeline should collect results and perhaps even halt a deployment if critical tests fail.
· Reporting and Alerts: Set up your CI to output test results in a readable form. Many CI tools can show test failures inline, or you can publish an HTML report artifact. Also, configure alerts (emails, Slack notifications) if certain tests fail – especially on mainline branches – so the team is immediately aware and can address issues. Tracking flaky tests (tests that fail non-deterministically) is important; some teams maintain a list of flaky tests and prioritize fixing them since flakiness can erode trust in automation.
· Version Control for Tests: Treat test code with the same rigor as production code. Keep it in the repository, do code reviews for test additions, and ensure changes to features come with changes to tests. This way, your tests evolve with the system.
By building a strong framework and process, you ensure that automation runs like clockwork and is not reliant on any one individual’s machine or memory. New team members should be able to get the test suite running easily, which encourages everyone to actually run and use the tests.
Maintenance and Continuous Improvement
One often overlooked aspect of test automation strategy is maintenance. Tests are code, and like any code they require upkeep. Over time as the product changes, tests need updating. There should be explicit effort allocated for this:
-
Refactor Tests When Needed: If you find multiple tests doing similar setup, refactor into a helper. If a particular page element’s locator changed, update it in the central page object or selector file (if you’re using the Page Object Model for UI tests, which is recommended to separate test logic from UI locator details). Remove or rewrite tests that no longer add value (for example, if a feature changed fundamentally, tests for the old behavior should be removed or replaced).
-
Watch for False Failures (Flakiness): Flaky tests – ones that sometimes pass, sometimes fail for non-bug reasons – can undermine the whole suite’s value. They may be caused by race conditions, timing issues, or test environment instability. Implement retries for certain tests if absolutely needed (some CI setups rerun failed tests a second time to see if it passes, marking it flaky). Better is to diagnose and fix the root cause: add proper waits in UI tests for elements to appear, increase resource allocation for performance tests, etc. Some modern frameworks have built-in smart waiting and self-healing to reduce flakiness.
-
Metric Tracking: Track metrics like how long test suites take to run, how many tests are failing regularly, code coverage of tests, etc. For instance, code coverage metrics (while not a goal by themselves) can highlight untested parts of the codebase, guiding where to add tests. If you notice test runtime creeping up, consider splitting tests to run in parallel or archiving tests that cover redundant scenarios. Many CI tools and dashboards can show trends of test failures or durations over time.
-
Regular Cleanup: Every so often (say, each sprint or at least once a quarter), dedicate time to cleaning the test suite. This might mean deleting tests for features that were removed, updating assertions that were temporarily tweaked, or improving test descriptions and documentation. Just as developers pay off technical debt in the codebase, treat test code debt seriously.
-
Involve the Whole Team: Ensure developers are on board with maintaining tests, not just QA engineers. When a developer changes code that breaks a test, the onus should be on them to fix the test (or consult with QA to update expected behavior). This shared ownership prevents the “test suite decay” that happens when everyone ignores failing tests because “not my job.”
By keeping maintenance a continuous activity, your automation stays healthy and trustworthy. A test suite with many broken or ignored tests is effectively no better than no tests – it might even be worse because it gives a false sense of security or becomes noise that developers tune out.
Example: Setting Up a Test Automation Pipeline (Step-by-Step)
To put it all together, let’s walk through a simple scenario of setting up test automation for a new web application:
-
Start with Unit Tests: As developers implement new modules, they write unit tests for critical functions (using JUnit). These run on their local machine and in CI on each push. The team sets a guideline like “all new business logic should have unit tests, and the CI will fail if any unit tests fail.”
-
Introduce Integration Tests: The app has a REST API and a database. QA engineers (with help from devs) write a set of integration tests that start the application in a test mode with an in-memory H2 database, load some seed data, and then make HTTP calls to the API to verify responses. These integration tests are written using a testing library like REST Assured or even JUnit + Spring Boot’s testing support (if it’s a Spring app). They run somewhat slower, so they are configured to run on each commit to a feature branch and nightly on the main branch. CI splits them across 4 parallel agents to speed up total time.
-
Add a Few UI End-to-End Tests: Using Selenium (or Cypress), they automate a few core user journeys through the web UI: user login, basic navigation, and a critical transaction (e.g., placing an order). These tests run using Chrome in headless mode on a CI agent, pointing to a staging deployment of the application. Because these are the most brittle, they run only on the main branch or maybe just before a release (and certainly can be run manually by QA when needed). The team limits these to maybe a dozen scenarios, and each is kept relatively short.
-
Static Analysis and Security: Developers also add a static code analyzer and run SAST (Static Application Security Testing) tools in the pipeline. For instance, SonarQube for code quality and ESLint for JavaScript code. These catch things like unused variables, potential null pointer issues, and some security hotspots automatically. The pipeline treats these kind of like tests – if the static analysis finds issues above a threshold, the build fails.
-
Continuous Integration Pipeline: The CI is configured such that:
-
On every pull request: run all unit tests and integration tests (maybe a subset if the suite is large, or the full set in parallel).
-
If all pass, allow the PR to be merged: If something fails, flag it for the developer to fix.
-
On merges to main, deploy the application: to a test environment and run the full integration test suite against it, then run the UI E2E tests and performance tests if any. Also run security scans. Only proceed with a release if these pass.
-
Provide quick feedback: unit tests finish in 2 minutes, integration in 5 minutes (with parallelization), E2E in 5 minutes – so within ~10 minutes of a merge, the team knows if there’s a problem.
-
Reporting: The results of tests are published. For example, CI posts a comment on the pull request like “✅ 152/152 unit tests passed. 💚 Integration tests all passed.” Or if something failed, it shows which test failed with logs. After nightly runs, a report is emailed to the team showing any flaky test or performance regression.
-
Maintenance Process: If a test fails due to a product change (e.g., a UI text changed and the Selenium locator needs update), the team prioritizes fixing it within the same development cycle. They avoid the temptation to just mark tests as “ignored” unless there is a very good reason (and if so, they track those and fix or remove them soon).
-
Metrics & Improvement: The team monitors code coverage (let’s say they maintain 80% coverage on core modules), and they notice if a particular component is under-tested and add tests accordingly. They also watch how often tests fail and why. If an integration test is flaky due to timing, they improve the synchronization. If an end-to-end test keeps failing due to a third-party service call, they might decide to mock that third-party out in the test to reduce false failures, or use a contract test strategy with that service instead.
Following these steps, the application enjoys a robust safety net. Developers have confidence to refactor code because if something breaks, a unit or integration test will likely catch it immediately. Test automation becomes an enabler of rapid development rather than a hindrance.
In the above scenario, one could imagine using a tool like Keploy to further streamline parts of the process – for example, capturing real API traffic to generate integration tests automatically, which could bootstrap the integration test suite quickly. We’ll talk more about Keploy shortly, but first, let’s summarize the benefits and challenges of test automation that we’ve touched upon.
Challenges and Pitfalls of Test Automation
While the benefits are compelling, implementing test automation is not without challenges. It’s important to be aware of common pitfalls so you can address them proactively:
-
Initial Investment and Skill Requirements: Setting up a good automation suite requires time, effort, and people with the right skills. There’s a learning curve for the team to pick up new tools or programming concepts (especially if manual testers need to transition into writing automated test scripts). The initial months of automation can feel slow – as you’re writing tests rather than moving on to new feature work. This investment pays off later, but it requires management support and team patience to not lose momentum early.
-
Maintenance Overhead: Automated test scripts are code, and as mentioned, they need maintenance. A major pitfall is underestimating this. If your application’s UI is changing rapidly, naive UI scripts will break often and require updates – failing to allocate time for this will result in a failing test suite that gets ignored. Tests that are not updated become more of a liability than an asset. It’s crucial to design tests to be as maintainable as possible (using good locators, abstractions, etc.) and to factor in maintenance as part of each sprint. Nonetheless, maintenance remains a challenge especially for large suites; one survey found teams reporting a significant portion of their testing effort goes into maintaining existing tests.
-
Flaky Tests (False Positives/Negatives): A flaky test is one that sometimes passes and sometimes fails without any changes in code, often due to timing issues, concurrency, or external dependencies. Flaky tests can seriously undermine trust in automation. If a test fails but the team thinks “oh, it’s just that flaky test again,” then a real bug might be ignored. Flakiness can come from things like: not waiting properly for web elements to load, relying on timing that varies, tests that depend on order (and thus fail when order changes), network instability if tests call external services, etc. Managing flakiness is a continual battle – it often requires improving the test code or environment. Some modern solutions involve using AI to detect flaky patterns or to auto-rerun tests to validate failures. But ultimately, each flaky test should be fixed or removed. One way to combat this is to isolate root causes: e.g., if an end-to-end test is flaky due to an external API, you could introduce a contract test for that API and mock it in the e2e test so the flakiness goes away.
-
Environment and Data Dependencies: Automated test scripts can be very sensitive to the environment they run in. If a test expects a certain database state or configuration, and the environment differs, the test fails not because of a code bug but a test setup issue. Managing test environments (spinning up clean containers, using in-memory DBs, etc.) is critical. Similarly, test data issues can cause headaches: tests might pass when run in isolation but fail when run together due to shared state or data not being cleaned up. A classic example is two tests creating a “user with username X” – if run in parallel, one might collide with the other. The pitfall is not designing tests to be idempotent and isolated. The solution is usually to have setup/teardown that ensure a known good state (e.g., resetting the database between tests or using unique data for each test). Utilizing test doubles for external systems also helps control the environment.
-
Over-reliance on Automation / Losing Exploratory Testing: Sometimes teams swing to 100% automation and fall into the trap of thinking automated test scripts will find all issues. Automation is great for checking expected conditions, but it’s not good at finding unexpected issues or assessing things like user experience. If a team neglects exploratory testing, they might miss important bugs (like an odd workflow bug that no one wrote an automated test scripts for, or a UI layout issue that an automated test script clicking buttons wouldn’t notice). It’s important to keep a balance – use automation to cover the obvious and repetitive, and free up time for human testers to do exploratory sessions on new features or risky areas.
-
Scripting the Wrong Things: A pitfall is trying to automate tests that are not good candidates, leading to frustration. For example, automating a complex CAPTCHA or a third-party integration test that relies on an external system that’s unstable. If you try to brute-force automate everything, you might spend inordinate effort for little gain or create a suite that’s inherently unreliable. It’s okay (even wise) to have a small manual checklist for certain scenarios rather than automation if those scenarios don’t fit automation well. Or invest in simulation of external factors rather than automating against the real thing.
-
Tooling and Integration Issues: Tools themselves can be a source of pain. Maybe the chosen automation tool has bugs, or it doesn’t integrate well with your tech stack. For instance, some GUI automation tools might have trouble with a custom UI component library. Or a cloud device lab might occasionally have connectivity issues causing test failures. Having good support (community or vendor) for your tools is important. Also, if your team uses many disparate tools (one for web, one for API, one for mobile, all with different languages), maintenance can be harder. Where possible, leveraging the same language/framework for multiple test types can reduce context switching (e.g., writing API and UI tests both in JavaScript).
-
Managing Test Data and Test Cases: As automated test scripts suites grow, managing the sheer number of tests and their data can become unwieldy. It’s a pitfall if tests become very large and monolithic (hard to pinpoint which part failed) or if there’s no clear mapping of what’s covered and what isn’t. Test case management practices can help, like tagging tests (e.g., smoke, regression, slow, etc.) and being able to run subsets easily. Also, generating or seeding data for tests is sometimes tricky – for example, performance tests might need large datasets. If not managed, tests might all run on the same data and potentially interfere with each other. Using techniques such as automated test data generation or resetting state through virtualization can mitigate this.
-
Cultural Challenges: Finally, there can be human/policy challenges. In some organizations, developers might think “testing is QA’s job” and not help with automation, leaving a small QA automation team overwhelmed. Or vice versa, testers might not have programming expertise and feel threatened or discouraged. Overcoming this requires cultural change – fostering collaboration (e.g., pair programming between dev and QA on tests), training team members, and possibly bringing in software engineers in test (SDET) roles who bridge the gap. Also, ensuring management values automation outcomes (like catching a bug in CI is as celebrated as preventing a production bug) so the effort is appreciated.
In summary, test automation isn’t a silver bullet – it introduces its own set of problems that need diligent engineering practices to handle. The good news is the industry has recognized these challenges, and both process improvements and new technologies are emerging to address them (for example, intelligent test automation using AI to reduce maintenance burdens, which we’ll discuss shortly).
Best Practices for Effective Test Automation
To maximize the value of test automation, consider the following best practices which have been distilled from industry experience:
· Design Tests for Independence and Repeatability: Each automated test case should be able to run on its own and in any order relative to others, yielding the same result every time. This means avoiding inter-test dependencies (e.g., Test B relies on Test A creating some data). If tests depend on a common state, that state should be set up in each test (or in a test fixture setup method). Teardown or cleanup steps should leave the environment as it was. Independent tests can be safely parallelized and won’t cause “cascading failures” when one fails.
· Use Meaningful Assertions (Verify Behavior, Not Implementation): Tests should assert externally observable behaviors or outputs, not internal implementation details. For instance, assert that “after API call, database has record X” or “UI displays message Y” rather than “internal method Z was called (via a mock)”. Focusing on behavior makes tests more resilient to refactoring. One caveat: unit tests will use mocks/stubs, but even then, use them judiciously to simulate true boundaries (like a database or network call), not to dig into internal calls unnecessarily.
· Keep Tests Simple and Focused: Each test case ideally verifies one thing (or a small set of closely related things). If a test script goes through an entire complex scenario with dozens of asserts, it becomes hard to debug when it fails. Better to break it into smaller tests for each logical checkpoint, if possible. This also follows the Single Responsibility Principle applied to tests.
· Leverage Test Data and Configuration Management: Externalize things like test data, URLs, credentials, etc., into configuration files or fixtures. This way, if something changes (say, the base URL of the test environment), you change it in one place. Use parameterization to run the same test with different data. For sensitive data like passwords or API keys, use secure ways to inject those in CI (like environment variables or secrets management) rather than hardcoding.
· Use Page Object Model (POM) for UI Tests: The POM pattern is widely recommended for Selenium/Cypress tests. It means representing each page (or significant UI component) as a class/object with methods to interact with it and query it. For example, a LoginPage object might have a method login(username, password) that enters credentials and hits submit, and perhaps a property errorMessage to retrieve any error text. Tests then call these methods instead of low-level Selenium calls. This decouples test logic from locator details. If the UI changes (say the login button ID changes), you update the Page Object’s locator in one place, and all tests that use it benefit. It makes tests more readable too.
· Aim for Speed and Parallelism: Fast tests encourage developers to run them often. Optimize tests to eliminate needless waits (but do use smart waits for events). If you have a large suite, invest in infrastructure to run tests in parallel – e.g., split tests across multiple CI agents. Many modern CI systems can parallelize jobs if you give them a way to divvy up tests. The quicker the suite runs, the more often it can run (like on every commit vs. nightly) which tightens feedback loops.
· Consistently Enforce and Evolve Testing Strategy: Make automated testing a required part of the development workflow. For example, enforce that all new features come with appropriate automated tests (this can be part of the definition of done). Code reviews should include reviewing test code quality. Also, revisit your strategy periodically – perhaps your pyramid shape needs adjusting as the product grows (maybe you need more integration tests now, or maybe some UI tests can be pruned because unit coverage improved). Keep the strategy aligned with current project needs.
· Monitor Test Results and Act on Failures Promptly: Treat a failed automated test as a mini incident. Investigate why it failed. If it’s a product bug, fix it or at least ticket it immediately. If it’s a test issue (flaky or outdated test), fix the test. Don’t let failures sit ignored; that leads to the “boy who cried wolf” situation where real issues get drowned in noise. Many teams adopt a “fail-fast” mentality – if the CI tests fail, they stop the pipeline, and developers swarm to fix the issue before continuing. This keeps the main branch always green and deployable.
· Track Metrics for Automation Effectiveness: As part of QA planning, track things like: test coverage (line or requirement coverage), number of defects found in production vs. during testing (ideally the latter goes up, the former down), flakiness rate, and test suite execution time. These metrics help identify where to improve. For instance, if deployment frequently gets delayed due to slow tests, that’s a signal to optimize tests or increase parallel nodes. If a certain portion of code has low coverage and also many bugs, focus new tests there.
· Include Non-functional Testing in Automation: Don’t stop at just functional correctness. If performance or security are important to your app, include those in your automated regimen. For example, have a nightly job that runs performance benchmarks and flags if response time degrades beyond a threshold (regression in performance). Or use a tool to run a suite of security tests (like OWASP ZAP for dynamic security scanning) automatically against a test instance. These help catch issues that functional tests might pass but still be problematic (like memory leaks, slow queries, or security vulnerabilities). It’s part of the holistic test automation strategy.
· Continually Refactor and Improve Tests: Treat test code with the same respect as production code. This means refactoring it for readability, removing duplication, improving structure, and deleting tests that are no longer useful. As new frameworks or libraries emerge that could make testing easier, consider adopting them. For instance, if you started with a lot of Selenium boilerplate but now you can use a framework like Selenide or Cypress that simplifies things, it might be worth migrating gradually. Improved tests (less flaky, more clear) directly translate to better productivity.
· Balance Preventative and Detective Approaches with Recovery: This ties to the earlier note from Fowler’s colleague: no matter how much testing, failures will happen in real usage. So while you prevent and detect issues with testing, also plan for mitigation and recovery. In practice, this could mean having feature flags to turn off a problematic feature if a bug is found post-release, or having good monitoring and alerting in production (like automated test scripts running in production or health checks) to catch issues early. It’s a good mindset to remember: tests increase confidence, but they don’t guarantee perfection. Having a rollback plan or quick patch process is a kind of safety net beyond tests.
Implementing these best practices isn’t always straightforward, but taking them on incrementally yields a more robust automation suite. Many of these practices have tool support (for example, linters or static analysis can enforce certain things in test code, CI templates can enforce test running, etc.).
By following best practices, teams ensure that their investment in automation keeps delivering value over time and doesn’t crumble under its own weight.
Now, on the horizon (and even starting to arrive) are the next generation of test automation improvements – particularly involving AI/ML. Let’s explore what the future holds for test automation and how tools like Keploy fit into that picture.
Future of Test Automation in Software Testing
The field of test automation is continually evolving. Several emerging trends and technologies promise to make testing easier, smarter, and even more integrated into the software development lifecycle. Here are some key directions where test automation is heading:
Rise of Intelligent Test Automation (AI/ML in Testing)
Intelligent Test Automation (ITA) refers to applying Artificial Intelligence and Machine Learning techniques to various aspects of testing. The goal is to reduce human effort in creating, maintaining, and analyzing tests. Some examples of how AI is being used:
-
Test Authoring: Tools that can observe user flows or read requirements and suggest or generate test cases automatically. AI can also learn from an application’s structure to create a model of possible interactions. For instance, an AI-driven tool might crawl a web application like a spider, then propose a suite of tests covering different pages and links.
-
Self-healing Tests: One of the biggest maintenance burdens is when a minor UI change causes many test scripts to break (e.g., a button’s ID changed). AI can help by using computer vision or other heuristics to identify the intended element. If a locator fails, the tool can automatically find the button by label text or visually by shape/color. Some tools claim to handle a large percentage (90%+) of locator changes without human intervention. This dramatically reduces flaky failures from changed UIs.
-
Predictive Analytics and Test Optimization: AI can analyze past test results and code changes to predict which areas are more likely to fail. This can enable smarter test selection – e.g., if you have 10,000 tests, an AI might predict which 500 are most relevant for a given change, so you run those first (or only those on a quick pre-commit check). AI can also prioritize testing based on usage patterns (like focusing on features users use most, which might be gleaned from production telemetry).
-
Bug Detection and Anomaly Detection: Beyond simple assertions, AI can detect anomalies that aren’t explicitly asserted. For example, it could notice that a page took much longer to load than usual or that a microservice’s memory usage pattern deviated from baseline during a test run. These could flag potential performance or memory issues that a human didn’t specifically write a test for.
-
Test Maintenance Analytics: AI could identify duplicate tests or tests that don’t add much value (e.g., tests that always pass and don’t exercise unique code). It might suggest eliminating or combining them, thus optimizing the suite.
-
Natural Language Processing (NLP) for Test Creation: We see early versions of this in tools where you can describe a test scenario in English, and the tool generates automated scripts for it. For example, “Log in as a regular user, go to the profile page, and verify the email can be updated” – an AI might interpret that and produce a script. This is still evolving, but with models like GPT-4, it’s increasingly plausible to go from natural language to code (indeed, some testers use ChatGPT to help write test code snippets today).
-
Visual Testing and Computer Vision: AI-powered visual validation can go beyond pixel-by-pixel comparison. Tools like Applitools use ML to distinguish meaningful changes from noise (like minor rendering differences). This provides robust visual regression testing that won’t false-alarm on every small anti-aliasing change, etc. As AI advances, it might even understand if a visual change is likely a bug or acceptable (e.g., detecting if a button is overlapping text – a human would call that a bug; AI is learning to spot such issues).
The promise of intelligent automation is to handle the “busywork” of testing – the grunt work of script writing and upkeep – so testers can focus on high-level test strategy and exploratory testing. It’s still early, but we’re seeing more products in this space.
Codeless and Low-Code Test Automation
We touched on this with some tools, but the future likely holds more codeless or low-code test creation options. The idea is to allow domain experts or less technical team members to create automation without writing code. Approaches include:
-
Record-and-Playback (with intelligence): Modern recorders (like those in Cypress or Selenium IDE’s new version) are more robust. They capture user flows and generate test scripts, but also allow inserting assertions and parameterizing inputs. While pure recording has a bad reputation (due to brittle scripts), augmented by AI self-healing and easy editing, it could make a comeback as a productivity booster.
-
Model-Based Testing: Users define models (flows, states, transitions) often in a visual way. The tool then generates test cases to cover the model (for example, covering every transition at least once, or particular paths). This removes coding from the equation – you’re drawing or configuring a model of the software’s behavior. Microsoft’s WinAppDriver and some MBT tools work this way, and future tools may make this more accessible.
-
Spreadsheet or Form-driven test definition: Some tools let you create tests by filling out forms or spreadsheets (essentially keyword-driven testing). For instance, a table where each row is a step (Keyword, Target, Data). This was popular in older frameworks (like HP’s UFT had keyword view), and it’s evolving into more user-friendly UIs now.
-
Codeless doesn’t mean powerless: The aim is that codeless tools integrate logic (like loops, conditions) in a visual way. Perhaps by dragging blocks (like Scratch programming but for tests) or using natural language: e.g., “Repeat the following steps until X is true” in plain English, which the tool interprets.
Codeless tools lower the entry barrier to automation. They also might speed up automation development for simple tests. The trade-off has been flexibility – historically, if your test scenario is complex, codeless tools struggled and you eventually needed to code. The future might blur that line by making the transition between codeless and code seamless (e.g., generated code that you can extend manually if needed).
We also see “automation as a service” offerings aligning with this: companies offering to do the heavy lifting of automation for you (either via outsourcing or via cloud platforms that automate tests based on your parameters). This leads to the next point.
Test Automation as a Service (TaaS)
“Test Automation as a Service” is an emerging delivery model where instead of building your entire automation solution in-house, you leverage external services. This can take a few forms:
-
Cloud-based testing platforms: These provide the infrastructure and often some level of test authoring help. For example, BrowserStack, Sauce Labs, LambdaTest, etc., provide device/browser farms so you don’t have to maintain that hardware. Some also offer recorders or IDEs in the browser to write tests, and dashboards to manage results. They essentially take care of the execution environment.
-
Outsourced automation engineering: Some companies specialize in automation and offer to develop and maintain your test suites for you (either with their own staff or by providing you a dedicated automation team on contract). This is more of a consulting/service engagement. The idea is you pay for outcomes (like “we will automate 80% of your regression tests in 3 months”) rather than hiring your own full-time automation engineers. This can work well for organizations that lack in-house expertise, but it requires close collaboration to ensure the external team truly understands the product.
-
AI-driven cloud testing services: There’s a breed of new services where you upload your application (or point the service to your running app), and the service automatically generates tests. It might crawl the app or use predefined templates. For example, a service might say “Give me your web app URL and I will generate basic CRUD tests for each form I find.” Or “upload your API spec, and I will generate and run tests for each endpoint” (this is something one could do with an OpenAPI spec and some heuristics). This is a kind of automated test generation on the cloud. Keploy itself fits partly in this space by capturing traffic and generating tests, which we’ll elaborate on soon.
-
Continuous Testing and Monitoring: Some companies offer combined monitoring and testing services – they will continuously run synthetic transactions against your production and test environments to ensure everything works (a blend of test and uptime monitoring). This can be considered a service that ensures quality continuously without your team having to set up the whole thing.
The benefit of TAaaS is to let teams focus on core development while experts or specialized tools handle the repetitive test work. It can also be more scalable in terms of infrastructure – for instance, running a million tests on demand in the cloud (by allocating hundreds of servers) then tearing them down, which would be impractical in a local lab.
Continuous Testing & DevOps Integration
The future will see testing even more tightly integrated into the DevOps pipeline. This means:
-
Shift-Left and Shift-Right: Testing moves left (earlier in pipeline, e.g., unit tests in pre-commit, integration tests in CI) and right (into production via monitoring, feature flag rollouts with testing in prod). Continuous testing implies tests run at all stages, and quality info is fed back to devs constantly. We already have a lot of shift-left; shift-right is growing (things like chaos engineering are a form of testing in production).
-
Test Data Management Automation: In DevOps, provisioning everything through code (infrastructure as code). Similarly, test environments and data will be provisioned on the fly. For example, when a feature branch is created, an ephemeral test environment spins up, seeded with synthetic data, tests run, and then it’s destroyed. This ephemeral environment concept (also called on-demand environments) is likely to become more common – it helps eliminate the “works on my machine / test env” problem and enables testing in isolation.
-
Quality Metrics as KPIs: DevOps emphasizes feedback and metrics. We’ll see more quality-related metrics (test pass trends, code coverage trends, mean time to detect defects, etc.) included in DevOps dashboards alongside deployment frequency and mean time to recovery. This elevates testing to a first-class citizen in the delivery process.
-
Collaboration & Unified Tooling: Testing tools will further integrate with dev tools (IDE plugins for writing/running tests easily, pull request checks, etc.). We already see that with things like GitHub Actions running tests on PR, but likely this will tighten such that perhaps as you write code, tests relevant to it auto-run in background (some IDEs do that partially).
AI and ML in Testing (Future Vision)
We covered intelligent automation, but to speculate a bit further: – We might see AI bots that act as a QA assistant: reading requirements or user stories and suggesting test scenarios, or even directly filing bug reports when something doesn’t match a spec. Imagine feeding the AI both the spec and the application (through an API or UI exploration) and it identifies mismatches.
-
Testbots for Exploratory Testing: AI agents could perform some level of exploratory testing – randomly clicking around but in a more informed way than pure random, trying various inputs, and monitoring for crashes or errors in logs. Some research tools do that (fuzz testing for UIs or game playing AIs for apps). They won’t replace human exploratory testers (because understanding usability or business impact is hard for AI), but they could be used to find obvious issues (like unhandled exceptions) automatically.
-
Learning from Production: ML could analyze production usage patterns and user journeys and feed that back into test creation – ensuring the test suite at least covers the most common user flows (or alternatively, create tests for edge flows that do occur but maybe weren’t thought of).
-
Contract Testing and AI: In microservices, contract testing is important (ensuring service A’s expectations match service B’s responses). AI could assist by analyzing service interactions and suggesting where contracts might break with a new code change.
All these futuristic ideas boil down to making testing more autonomous and smart. The human role will shift to overseeing, verifying critical scenarios, and dealing with the creative side of quality, while the rote execution and even generation of tests could be increasingly automated.
Now, amidst these trends, let’s talk about Keploy – an example of a modern tool that aligns with these future directions, using AI and automation to simplify testing, particularly for integration and API tests.
Keploy’s Role in Evolving Test Automation Practices
In the evolving landscape of test automation, Keploy stands out as an innovative solution that addresses several of the challenges we discussed by leveraging AI-driven automation. Keploy is an open-source test automation platform focused on API, integration, and unit testing. Its goal is to help developers and teams achieve high test coverage with minimal manual effort by automatically generating test cases and mocks from real application traffic.
Here’s how Keploy contributes to modern test automation practices and future trends:
-
Automated Test Case Generation: One of Keploy’s core features is the ability to capture real API calls and responses from your application and convert them into test cases. For example, you can run your application (perhaps in a staging environment or during a QA session) and let Keploy record the HTTP interactions (including request payloads, responses, and even database queries). These recordings can then be transformed into reproducible integration tests. This saves enormous time in writing tests. It’s essentially a form of record-and-playback on the API level. By basing tests on actual traffic (like production or realistic usage), it ensures the tests reflect real user scenarios. This approach aligns with the trend of using AI/automation to reduce the test authoring burden – instead of manually writing assertions for each field, Keploy does it automatically by comparing against the recorded baseline.
-
Mocking and Service Virtualization Built-in: Keploy not only records API calls but also records the downstream effects such as database calls or calls to other services, and it can generate mocks/stubs for those. When you replay the tests, Keploy simulates those external interactions. Essentially, it creates a sandbox for your service under test. This addresses the challenge of integration vs. integrated tests: you can test your service in isolation (focusing on integration points) without needing all dependencies to be up and running, and without writing a bunch of manual mock logic. It automates the creation of test doubles. For instance, if your service calls a payment API, Keploy can capture the outgoing request and the response that API gave, and during replay provide that same response without hitting the real API. This yields deterministic, fast integration tests that mirror production behavior. By doing this, Keploy helps achieve the “honeycomb” style testing – lots of integration tests, no flaky external dependencies – with much less effort.
-
High Coverage with Minimal Effort: Keploy advertises getting to 90%+ test coverage in minutes. While that figure may depend on the app, the concept is that by using your application’s real behavior to generate tests, you cover most code paths that are actually used. It effectively reduces the gap between how the app is used and how it’s tested. Traditional unit tests might have high coverage but not represent real usage patterns; Keploy’s tests are literally derived from usage, so coverage and relevance are both high. This boosts confidence significantly.
-
“Tests as Documentation” and Faster Onboarding: Since Keploy’s generated tests capture the inputs and outputs of your APIs, they serve as living documentation of what the service does. New developers can look at the Keploy test cases to learn the typical requests and responses. And because these tests are automatically kept up-to-date by re-capturing traffic when things change, the documentation doesn’t go stale. It also helps in refactoring – if you refactor internal code and the tests still pass (or if they fail only where behavior changed intentionally), you know your changes didn’t break contracts.
-
Integration into CI/CD and PR Workflow: Keploy can be integrated into CI pipelines so that the tests it generates run as part of your automated suite. Additionally, features like a GitHub PR agent (Keploy’s Unit Test GitHub App) generate unit tests for new pull requests automatically. This is cutting-edge – every time a developer opens a PR, an AI agent could create unit tests for the changed code and add them to the PR. It essentially shifts testing even further left, right into the code review phase. By doing so, Keploy can enforce higher coverage and catch issues earlier. A developer might be pleasantly surprised to see “Keploy bot” adding a commit to their PR with new test files that cover the code they just wrote. This addresses the scenario where developers might skip writing tests; Keploy assists or even does it for them, ensuring consistency.
-
No-Flake, Reliable Tests: Because Keploy uses the exact observed outputs as the baseline, the tests are asserting exactly those values – no ambiguity. Also, since it replays with mocks at the boundaries, there’s no variance in external systems. If something does change (say an API now returns an extra field or a different value), the test will fail, signaling a behavior change. You can then update the baseline by re-running the capture. This approach results in tests that “only fail for useful reasons” (to borrow Justin Searls’ phrase from Fowler’s article) – meaning a failure likely indicates a real contract change or regression, not a flaky network call or timing issue. By reducing false failures, Keploy increases trust in the test suite.
-
Accelerating Microservice Testing (Honeycomb/Diamond Implementation): In a microservice architecture, writing integration tests for each service can be complex due to all the dependencies. Keploy simplifies this by recording inter-service calls and database operations for each service. It essentially provides a way to do microservice contract testing and integration testing in an automated fashion. Instead of manually writing a bunch of contract tests for each API endpoint and updating them whenever the API changes, you can use Keploy to generate those tests from real interactions. This makes adopting a honeycomb strategy much more feasible in practice – you can focus on integration tests for each service knowing Keploy handles the scaffolding. It decouples tests from implementation, as Spotify espoused (decouple tests from code internals and focus on interface behavior).
-
AI and ML Under the Hood: Keploy leverages smart algorithms to do things like identify which parts of an API response are deterministic vs. which vary per call (e.g., timestamps or IDs that shouldn’t be hard-asserted). It can automatically ignore or parameterize those. This is a practical use of AI – understanding data structures to avoid false failures on dynamic fields. This kind of intelligence is what “intelligent test automation” is about – offloading analysis to the tool so you don’t have to hand-hold every assertion. Moreover, Keploy’s approach of learning from traffic is an example of machine learning from production data to improve testing – aligning with the future trend we mentioned.
-
Developer-Friendly and Open Source: Being open source, Keploy invites developers to try it without heavy procurement or licensing. It’s designed for developers in mind, integrating with languages like Go, Java, etc., through SDKs or wrappers. This is key because one hurdle in automation is often adoption; a tool that fits nicely into a developer’s workflow and is free to use will likely see more uptake. It encourages a culture where developers run Keploy to generate tests as they build new features or when they fix bugs (to capture the scenario that caused a bug and then use it as a regression test case).
-
Futuristic Features & Competitive Advantage: Compared to traditional automation, Keploy’s USP is the automation of automation – it automates the creation of tests and mocks, which is a level above tools that only help you run tests. Its focus on integration tests addresses a gap left by many tools that emphasize unit or UI testing. By dealing with APIs and integration, Keploy positions itself in a sweet spot for backend-heavy applications and microservices, which are common in enterprise today. The competitive advantage is saving engineer hours while increasing coverage and confidence. In a sense, Keploy can be seen as bringing the efficiency of record-playback testing (fast test creation) together with the rigor of programmatic testing (version-controlled, reusable, maintainable tests) without the usual downsides of record-playback (like brittleness), because it marries it with data intelligence and version control of test artifacts.
In practical terms, teams using Keploy have found they can rapidly bootstrap testing for legacy services that had little coverage – by replaying production traffic to generate a safety net of tests before refactoring. This is immensely valuable: legacy code often lacks tests and is risky to change; Keploy offers a path to safer modernization by capturing current behavior as tests.
Real-world scenario: Imagine a fintech company with dozens of microservices. They want to adopt the testing trophy/honeycomb approach but writing so many integration tests is daunting. They deploy Keploy in their staging environment, run their integration suite or even direct some mirrored production traffic through staging, and Keploy generates hundreds of test cases across their services. Now they integrate those into CI. Suddenly, their coverage jumps and they have a regression suite ready. Developers now get failing tests when they inadvertently change an API contract or logic – essentially immediate feedback on things that would have been caught later by manual QA or not at all. This accelerates their DevOps pipeline and increases reliability, giving them a competitive edge in shipping features quickly with confidence.
To sum up, Keploy exemplifies several themes we discussed:
-
Intelligent test creation (AI analyzing traffic to produce tests),
-
Focus on integration level (modern test strategy aligned with how systems are built today), – Automation as a Service (it provides a service to record and generate tests for you),
-
Bridging Dev and QA (making it easy for developers to have tests without doing all the grunt work).
In the future, we can expect Keploy to evolve further – perhaps more AI to optimize tests, maybe generating performance tests or security tests similarly from observing patterns, etc. But even in its current form, it’s a powerful ally for teams aiming for high-quality software without slowing down development.
Conclusion
Software testing and test automation have come a long way – from the early days of manually testing code modules to today’s sophisticated, AI-augmented testing pipelines. In this journey, we’ve seen how fundamental strategies like the Test Automation Pyramid emerged to guide us in balancing speed and confidence*.* We traced the evolution through critiques and refinements: acknowledging the pitfalls of the ice-cream cone anti-pattern (over-relying on slow manual tests), adopting agile practices with the Testing Quadrants to ensure a full-spectrum approach, and exploring modern models like the Testing Honeycomb and Testing Trophy that emphasize testing at the right level for today’s architectures.
The key lesson is that no matter the shape of our testing model, the ultimate focus should be on risk-driven testing and maintaining quality at speed. High-performing teams don’t debate whether they have 50% or 70% integration tests – instead, they ensure that for each change, there are reliable automated checks in place to catch bugs quickly, and that those checks are as close as possible to how the software is actually used. In practice, this means writing tests (or generating them) at multiple levels: unit tests to catch low-level bugs, integration tests to ensure components work together, and a few end-to-end tests to simulate critical user journeys – all complemented by exploratory testing and monitoring in production.
Effective test automation is a cornerstone of DevOps and continuous delivery. It enables teams to ship updates to users with confidence and frequency. We highlighted best practices such as keeping tests small and independent, using proper design patterns (like Page Objects) for maintainability, and integrating testing into every step of development – from code writing (TDD/BDD) to deployment (smoke tests, canary releases). When done right, test automation is not a bottleneck but a velocity booster: developers can move faster because they trust that if they make a mistake, the automated safety net will catch it within minutes.
Of course, challenges exist. Test suites can become fragile or burdensome if not tended to. That’s why continuous improvement of the test suite is vital – refactoring tests, eliminating flaky tests, and adopting new techniques (like AI tools) to reduce maintenance. The introduction of intelligent test automation is a game-changer in this respect. We’re already seeing AI cut down the effort in test creation and maintenance by self-healing locators and even writing test code. This trend will only grow, allowing teams to concentrate on high-level quality goals while routine testing tasks are handled by machines.
Tools like Keploy are at the forefront of this new wave, automating the hardest parts of testing (like writing integration tests and managing test data) and fitting neatly into modern development workflows. By adopting such tools, organizations can leapfrog years of building test suites and get instant feedback on their application’s behavior. It exemplifies how embracing innovation in testing can solve age-old dilemmas (who has time to write all these tests?) with fresh solutions (let the tool generate tests for you from real usage).
In conclusion, test automation in software testing is not just a “nice-to-have” – it’s a critical enabler of quality and agility. A robust automation strategy, when combined with sound testing practices and the right tools, yields numerous benefits: faster releases, fewer production bugs, happier developers, and more satisfied users. As you implement or refine test automation in your team:
-
Think big, start small: Aim for a high level of automation but iterate – begin with the most valuable tests (perhaps a smoke test suite) and gradually expand coverage.
-
Invest in your tests: Treat them as a first-class deliverable. Well-crafted tests will save you countless hours down the line.
-
Leverage modern tools and approaches: Don’t hesitate to try out AI-driven tools or new frameworks that can reduce toil. The field is moving fast – what was hard yesterday (like capturing baseline interactions) might be automated today.
-
Foster a culture of quality: Everyone from developers to QA to product should value and contribute to testing. When a bug sneaks past, rather than blaming, use it as a learning opportunity to improve your tests or process.
-
Prepare for the unexpected: Even with all testing, failures in production can happen. Have monitoring, alerting, and rollback mechanisms (like feature flags) in place. In complex, continuously changing systems, resilience is as important as prevention.
Ultimately, effective test automation gives your team confidence – confidence to refactor boldness, confidence to deploy frequently, and confidence that your software meets the high standards of quality that users expect. In a world where software is eating the world and everything is connected, that confidence (backed by a solid web of tests) is what allows you to move fast without breaking things.
By embracing the strategies, tools, and best practices outlined in this guide, teams can navigate the ever-increasing complexity of software systems. Test automation will catch issues early, act as a guardrail for rapid development, and free up human creativity for the kinds of testing that truly require insight and intuition.
As we unlearn outdated ideas and adopt new realities – treating deployment as just the beginning of feedback, understanding that test coverage is a measure of confidence not a guarantee, and balancing preventive testing with reactive recovery – we stand well-equipped to deliver robust, reliable software in the modern era.
In short, test automation empowers development teams to deliver better software, faster. It’s an investment that pays dividends in quality, reliability, and peace of mind. With the right approach, you can turn testing from a chore into a competitive advantage. Happy testing and automating!

Leave a Reply