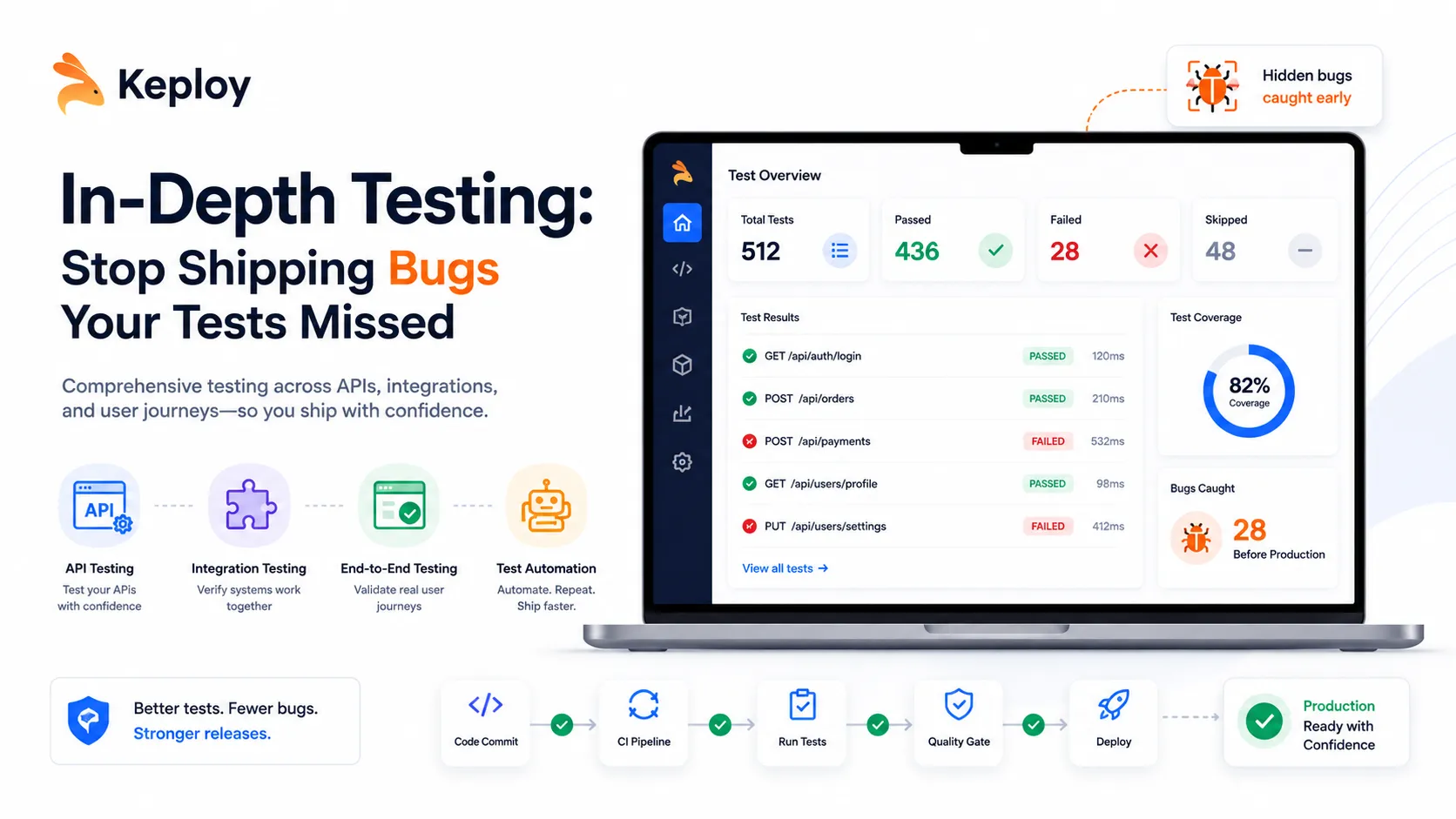
I’ve pushed code that cleared every CI check, watched the green badge appear, shipped to production — and then spent the next two hours on a rollback. That experience was my real introduction to in-depth testing. In-depth testing is the practice of validating software behavior across multiple layers: unit logic, component interactions, end-to-end user flows, and failure conditions. It’s not a tool you install — it’s the discipline of asking harder questions before your users find the answers. Most codebases I’ve contributed to treat passing tests as proof of correctness. The gap between those two things is exactly where production bugs live.
The green badge on your README doesn’t tell you what your tests skipped. I’ve seen repositories with 400 unit tests and 85% coverage that broke completely the moment someone ran them against a real database with an unusual SSL configuration. Coverage percentages measure lines touched, not behaviors validated.
What Is an In-Depth Test?
An in-depth test isn’t a specific test type — it’s a standard for how thoroughly you validate software across the scenarios that actually matter. This means checking not just that functions return the right values, but that components integrate correctly, that users experience what you intended, and that your system handles failure conditions without silently swallowing errors.
Deep testing spans the full validation spectrum:
-
Unit tests — isolated checks on individual functions or modules
-
Integration tests — verification that components interact correctly with databases,
queues, and external services -
End-to-end tests — simulated real user flows from input to final outcome
-
Edge case coverage — boundary inputs, empty states, malformed data
-
Failure path testing — what happens when dependencies return errors or go offline
In-depth testing means deliberately asking "what else could break here?" every time you write a test case — and then actually writing those tests instead of shipping anyway.
Why Most Test Suites Are Shallower Than They Look
I’ve contributed to enough open source projects to recognize the pattern immediately. The README shows a passing badge. The coverage report is in the low 80s. Then a user files an issue: "completely non-functional when the Redis connection drops mid-request." The test suite had never exercised that path.
Coverage metrics lie in predictable ways:
-
Line coverage misses behavior coverage. A test can execute a code line without testing what that line actually does under varied conditions or inputs.
-
Unit tests dominate because they’re fast to write. Integration tests require real infrastructure and more setup, so teams deprioritize them and rarely circle back.
-
Happy-path bias is nearly universal. Developers write tests for the scenario they designed the feature around, not the 12 ways a user might accidentally break it.
-
Excessive mocking creates false confidence. When every external dependency is mocked, you’re testing your assumptions about those dependencies — not how the real system
behaves.
Stripe’s engineering team has published about the compounding cost of shallow test suites: bugs that clear every test stage and only surface in production because the test environment never reflected real runtime conditions. That pattern repeats across every stack, every language, every team size.
The Three Layers Every In-Depth Test Strategy Needs
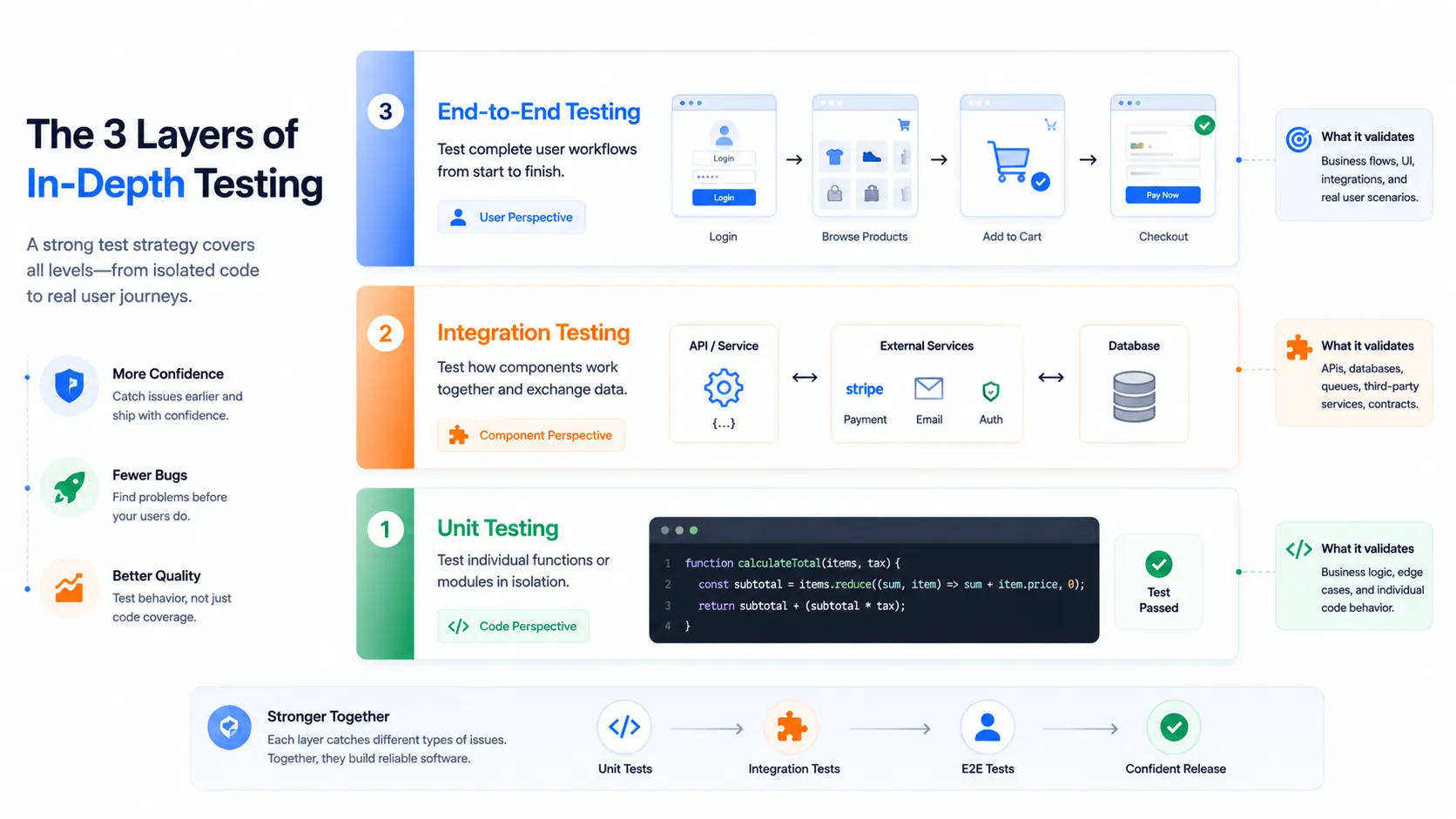
Unit Tests: The Starting Point, Not the Finish Line
Unit tests are fast, deterministic, and easy to write — which is also why they get over-relied on. A unit test confirms that a function returns the right output for a given input in isolation. It tells you nothing about whether that function behaves correctly inside a live database transaction, alongside a caching layer, or when an upstream API returns an unexpected status code.
Write unit tests for your business logic. But treat them as the entry fee for a test suite, not the full investment. If your test plan starts and ends with unit tests, you have a coverage percentage, not a testing strategy.
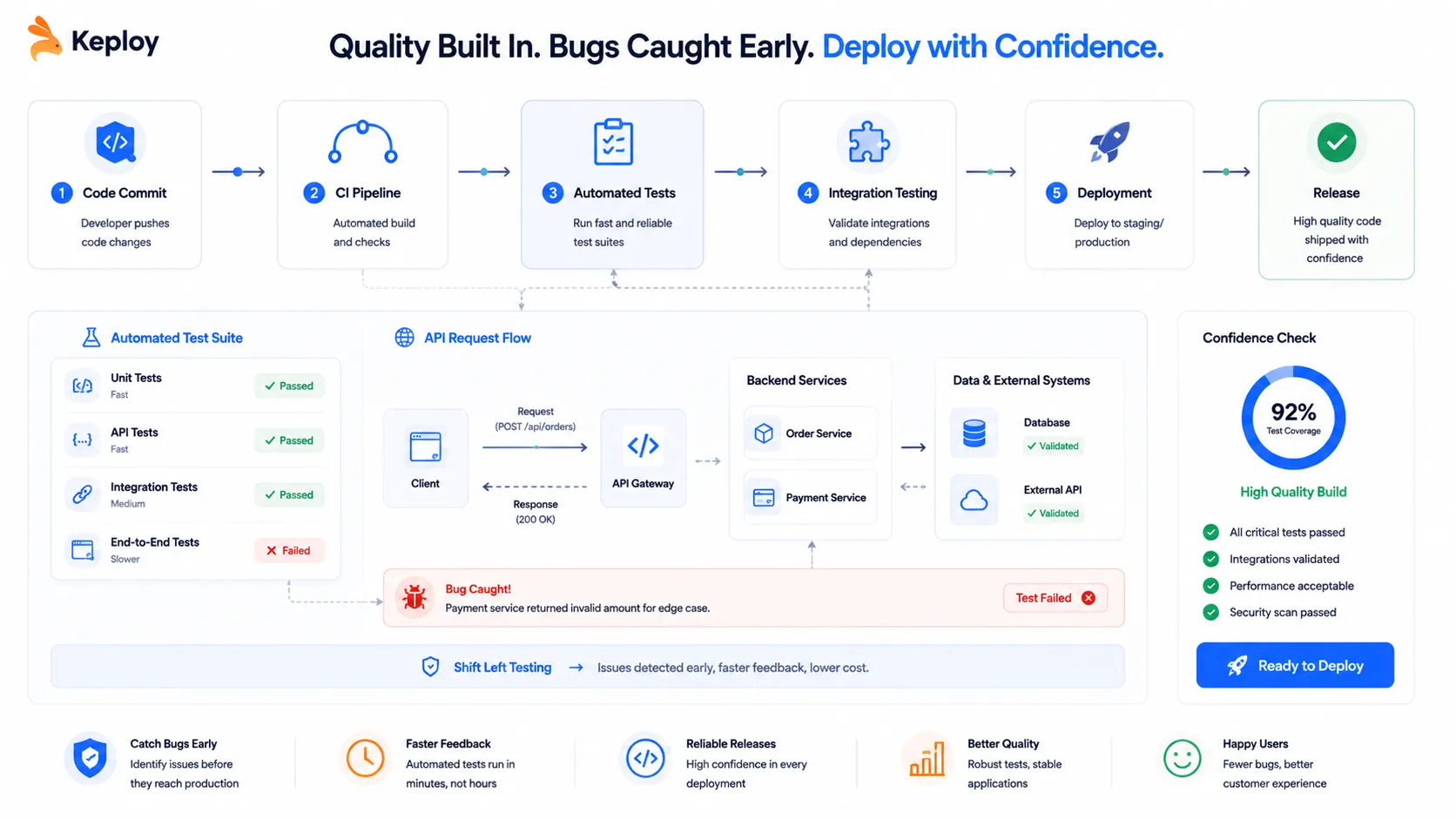
Integration Tests: Where Most Production Bugs Actually Hide
Integration tests verify that components work correctly together. An API handler talking to a real database, a service publishing to a message queue that another service consumes, a session store that should invalidate on logout — these are the seams where bugs live.
In a side project I worked on last year, an integration test caught a race condition in a Redis-backed session store that 200 unit tests had completely missed. The fix took 20 minutes to write. Without that integration test, it would have been a 2 AM incident with unclear root cause.
Tools worth using for integration testing:
-
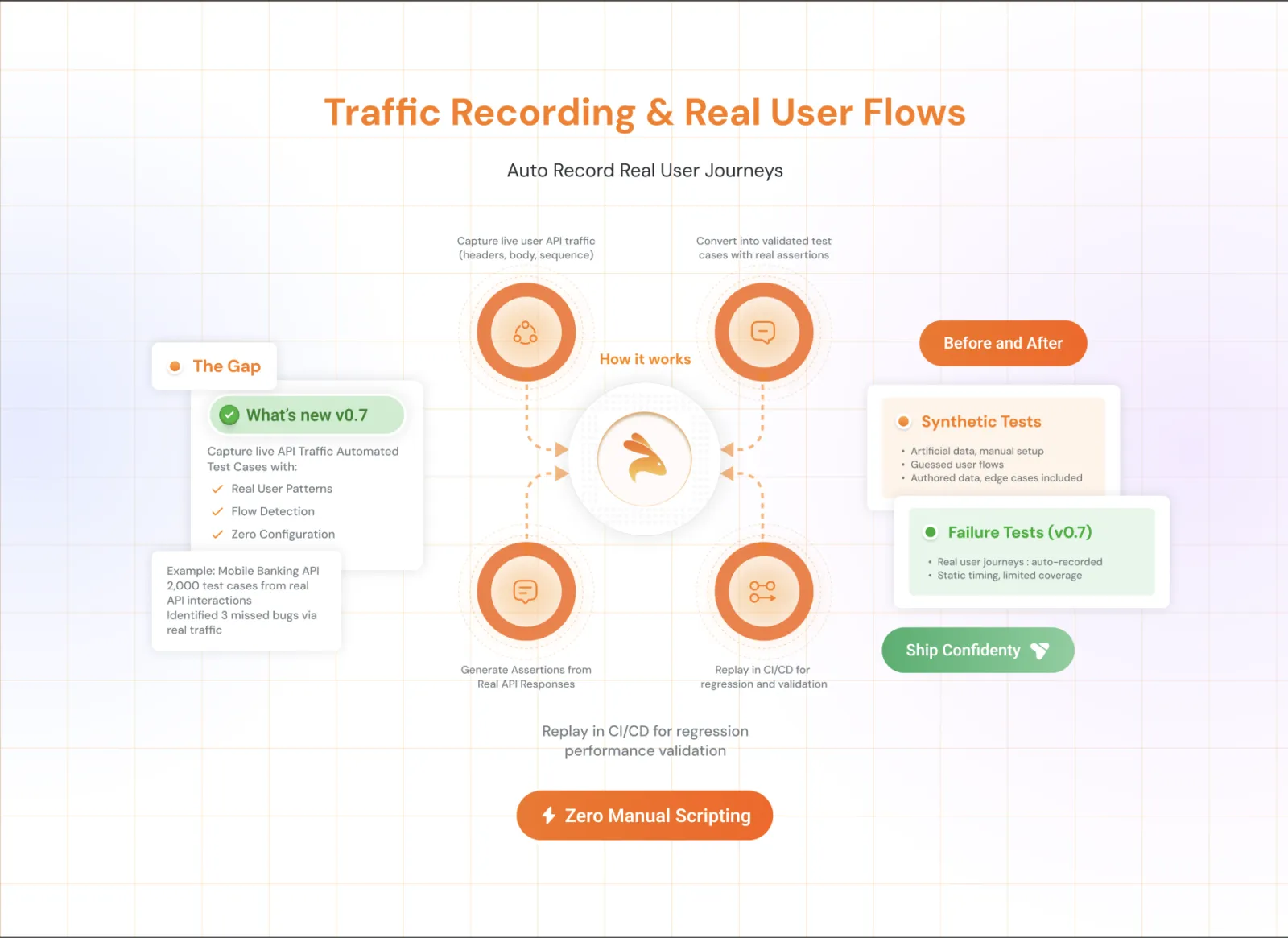
Keploy — records real API traffic and generates integration test cases automatically, so your tests
reflect how your service is actually called in the real world -
Testcontainers — spins up real databases and services in Docker for each test run, eliminating the "works on my machine but not in CI" class of problem
-
WireMock — controlled HTTP stubbing for external APIs you genuinely can’t run locally
End-to-End Tests: The View From Your User’s Seat
E2E tests simulate what a real user does inside your application. They’re slower to run, more expensive to maintain, and the most fragile test category — but for critical flows like authentication, checkout, and onboarding, nothing else fully replaces them.
Playwright has become the practical standard for most teams I’ve seen. It handles async flows reliably, has solid debugging tooling, and runs consistently in CI environments. For API-focused applications specifically, Keploy’s traffic recording approach gets you E2E-level confidence without the brittle selector maintenance that comes with UI automation.
The key principle with E2E tests is selectivity. Test the flows where failure causes direct user pain or revenue loss. Don’t chase 100% E2E coverage — the maintenance cost isn’t worth it when your integration layer is already strong.
Signals That Your Test Suite Needs More Depth
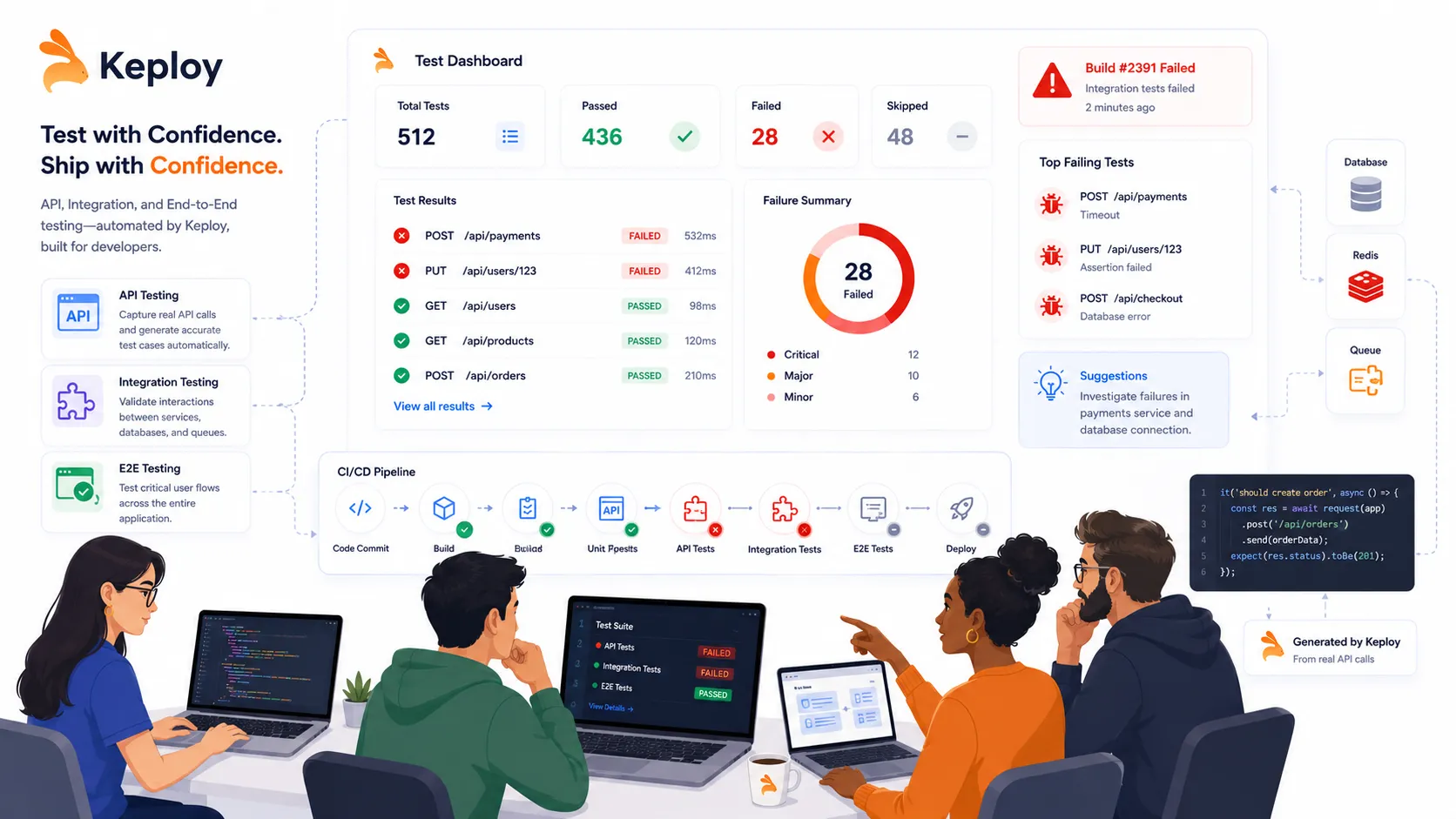
Before building a strategy, it helps to know where your current tests are weakest. Here are the signals I look for when evaluating a codebase:
-
You feel nervous before every production deploy
-
Most of your bugs get discovered by users, not caught by tests
-
Your CI passes consistently but staging always has issues
-
You added a mock to make a test pass rather than to reflect real behavior
-
Integration test failures get labeled "flaky" and ignored instead of fixed
-
New contributors regularly break things that weren’t covered in the test suite
If three or more of these apply, your test suite has depth problems. The good news is that targeted integration test investment fixes most of them.
Building a Deep Testing Strategy That Actually Holds
Here’s what I’ve seen work across different codebases and team sizes:
Define what "tested" means for your team before you write tests. "80% coverage" is a metric, not a behavioral guarantee. Write down the specific behaviors your application must uphold — API contract obligations, data integrity guarantees, auth flow correctness — and test those behaviors directly. Coverage is a side effect of good testing, not the goal.
Move integration tests into CI on every pull request.
Don’t save integration testing for a pre-release phase. Finding a broken integration at merge time costs 20 minutes. Finding it post-merge can cost hours and a rollback. Yes, your pipeline gets slower. That is the right trade.
Use real traffic to guide where you invest test effort.
The most valuable tests reflect how users actually use your software. Keploy captures real API calls from staging or production and converts them into reproducible integration test cases. You get coverage grounded in real usage patterns, not imagined scenarios you invented at the time of writing.
Test failure paths with the same rigor as success paths.
What does your service return when the database is at capacity? What happens when an upstream dependency times out after 30 seconds? What does the client receive when a background job fails silently? These paths need explicit tests — not just assumed error handling that nobody has verified.
Audit your mocks on a schedule.
Every mock is a bet that the real dependency behaves exactly as you assumed when you wrote the test. Take your most heavily mocked integration, remove the mock, run it against the real system. Do this quarterly. The results are usually instructive.
Deep Testing in Open Source Projects
Open source maintainers feel the cost of shallow testing more acutely than most. A contributor opens a clean-looking PR, CI passes, it gets merged — and within a week there are three new issues from users running slightly different environments or configurations.
The repositories I trust on GitHub share a consistent pattern. They run integration tests against real services in CI. They have explicit test coverage for error states and edge inputs, not just happy paths. Their contribution guidelines require behavioral test coverage, not just coverage percentage increases. Projects like Kubernetes, Temporal.io, and Keycloak have invested significantly in deep testing infrastructure — and their production stability reflects that investment.
For your own projects, even small ones, a handful of well-written integration tests for your critical paths does more for contributor confidence than 200 additional unit tests. It also signals that the project takes correctness seriously, which tends to attract higher quality contributions over time.
Common In-Depth Testing Mistakes
| Mistake | Why It Hurts | Fix |
|---|---|---|
| Measuring only line coverage | Misses behavior coverage entirely | Define explicit behavioral test requirements |
| All unit tests, no integration tests | Hides real failures at system boundaries | Add integration tests for key component |
| interactions | ||
| Mocking every external dependency | Tests your assumptions, not the system | Use real dependencies in integration environments |
| Only happy-path test cases | Misses the bugs users actually encounter | Write explicit tests for error states and edge inputs |
| Letting flaky tests accumulate | Erodes trust in the entire test suite | Fix or delete every flaky test — never let them sit |
Frequently Asked Questions
What is the difference between in-depth testing and code coverage?
Code coverage measures what percentage of your code lines execute during tests. In-depth testing is a strategy that asks whether you’re validating the right behaviors — including integration points, failure modes, and edge cases. You can achieve 100% line coverage and still ship serious production bugs. Coverage is a data point; in-depth testing is a standard for what those tests actually verify.
How does deep testing differ from regression testing?
Regression testing ensures existing functionality keeps working as the codebase changes. Deep testing describes how thoroughly you validate any given behavior — including failure scenarios, multi-component interactions, and real-world edge cases. A strong regression suite is built on deep testing principles, but regression testing is one application of those principles, not the same thing.
When should a team start investing in in-depth testing?
Earlier than feels necessary. Retrofitting integration tests into an established codebase is slow and expensive — you’re working against existing architecture decisions and fighting to understand system boundaries that could have been documented through tests. If you’re building something new, start integration tests for your critical paths from day one. If you’re in an existing codebase, start with your highest-risk paths: auth, payments, data writes, and anything with an external dependency.
Can automated tools replace manually written in-depth tests?
Automated generation tools — including Keploy’s traffic recording approach — build integration test coverage quickly and from real usage data. They generate tests from observed behavior, which means they cover real usage patterns well but can’t anticipate failure scenarios that haven’t occurred yet. Use automated generation to build a strong baseline fast, then supplement with manually written tests for edge cases and explicit failure path coverage.
What is the single highest-value change a team can make to improve testing depth?
Add integration tests for your three most critical API endpoints or service interactions. These tests surface real bugs faster than any other investment. If you’re not sure which three to pick, look at your incident history. The patterns are almost always obvious in retrospect, and the tests practically write themselves once you know what to cover.
Stop Treating Green CI as a Safety Net
In-depth testing doesn’t show up on a product roadmap. It doesn’t generate a visible sprint deliverable. It’s the difference between a codebase you deploy confidently and one where every merge carries a quiet knot in your stomach.
Start with your integration test gaps. Audit the mocks that are substituting for real dependencies. Test what actually breaks under real conditions, not just the scenario you designed the feature for. The compounding return — fewer incidents, faster debugging, lower on-call burden, better contributor confidence — is measurable and real.
If you want tooling that speeds up building integration test coverage, check out Keploy’s documentation — it captures real API traffic and turns it into reproducible test cases, which is one of the more practical paths from a shallow test suite to a genuinely deep one.

Leave a Reply