
Fast-paced development environments can no longer afford to treat quality assurance as an afterthought, and that’s why fitted into the development cycle. One of the most efficient methods available for evolving your testing strategy, is Data Driven Testing(DDT). But, what is data driven testing, and why is essential to automated QA pipelines?
This blog post serves as a guide for everything you wanted to know about Data Driven Testing: from defining it, identifying some of its advantages, methods to implement it, examples of real world use, and best practices. Finally, whether you consider yourself a developer, QA engineer, or technical writer, this blog post will help you identify the "why", the "what", and the "how" of it.
What is Data Driven Testing(DDT)?
Data Driven Testing (DDT) utilizes test inputs and originally expected results in external data sources such as Excel, CSV, JSON, or databases. As you run automated test scripts, the test inputs and results are fed in to automate the process. Instead of hard-coding values, you keep the logic of the test and change the data allowing for improved re-usability, and greater test coverage.

Example:
You are testing a login form as the user enters different username and password combinations. Instead of writing a test for each different credential combination, you store all credential sets in a data file. Then you iterate through the credential file in one reusable script, instead of writing potentially dozens/hundreds of duplicate tests. This allows for ease of maintainability, it allows for better test coverage.
Why Use Data Driven Testing?
If the tester is using traditional manual testing or even script-based testing, every time a test scenario is changed (or a new test scenario is added) the actual code is changed. In return, this raises maintenance costs and increases risk. Data Driven Testing will eliminate this, because the tests logic is completely independent from the test data.

These are the main reasons to implement DDT:
-
Efficiency: Reduce redundant code and risk of manual updates.
-
Scalability: Increase test coverage, simply by adding rows of new data.
-
Flexibility: Update the test cases without touching the logic.
-
Consistency: Run the same test under varying conditions, to validate system behavior.
-
Collaboration: Allow non-developers to add to testing through maintaining external data files.
Types of Data Driven Testing
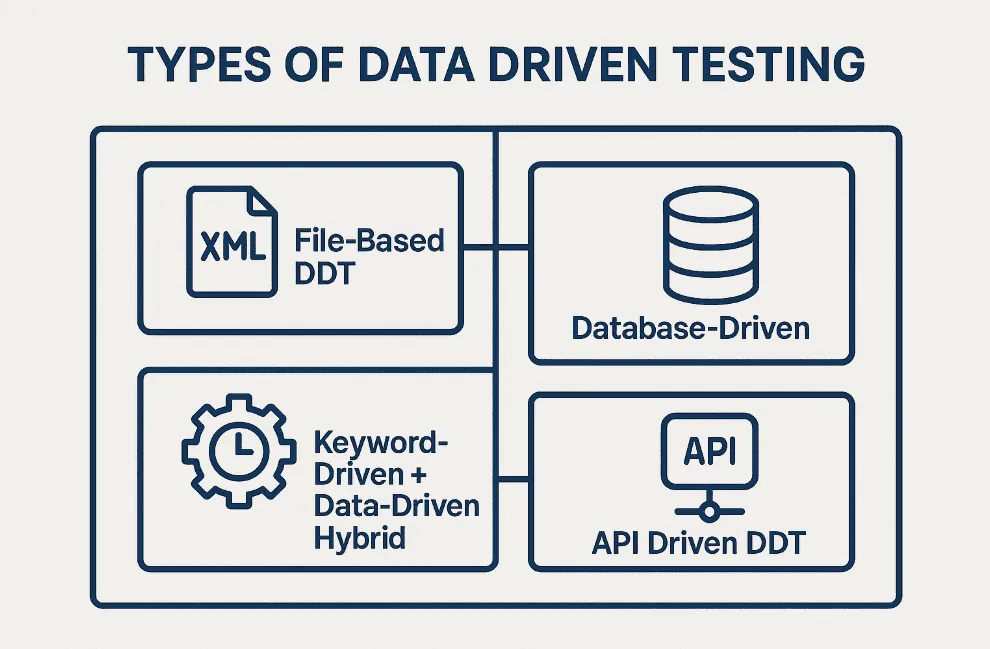
1. File-Based DDT
This is the most basic way to store data and it is when you import data temporarily from CSV, Excel, JSON, or XML files. The files are parsed at runtime and the data is processed in an execution of a test script to drive more of the test logic.
2. Database-Driven
In Database-Driven Testing, test data is stored in relational or NoSQL database. With this approach, you are able to execute tests using either live data or simulate real-world data scenarios.
3. Keyword-Driven + Data-Driven Hybrid
You use a Keyword-Driven technique (where the keywords actually control and drive the execution flow) to combine with DDT for a more powerful and comprehensive test framework and data driven test frameworks are more valuable with large scale enterprise applications.
4. API Driven DDT
In microservices and backend test environments this technique is particularly valuable. By associating API requests where you can use external test data to pass in different request bodies, headers, or expected responses for the same test case.
What is DDT in Automation
While DDT is not just for automation, it does provide incredible power when used in the context of automated testing. Most of the popular automation frameworks such as JUnit, TestNG, PyTest, and Postman, provide a feature that allows you to use a data source with parameterization in your tests, and iterate over the testing data.
When implemented in automation you:
-
Create a single test logic file.
-
Feed it structured input data.
-
Compare actual outputs to expected results.
This will greatly reduce the number of scripts you need to maintain while improving maintainability overall.
What is Data Driven Testing in API Testing?
API testing often requires multiple scenarios, including valid requests, error scenarios, authentication tests, and edge cases. It can be inefficient to manually code all the possible combinations. With a Data Driven Testing (DDT) approach you can actually:
-
Save your different API request payloads, along with the expected responses in JSON or CSV files.
-
Parameterize your test cases so that they can dynamically read those inputs.
-
Automate the comparison between actual and expected responses.
There are also tools such as Keploy that can help you with data driven testing within an API back end environment.
Benefits of Data Driven Testing

1. Enhanced Test Coverage: DDT allows you to create a broader scope of test scenarios using more input data without the need to write separate scripts.
2. Reusable Test Logic: The same test can be run with different data in various modules or versions as you separate the logic and data.
3. Reduced Maintenance Overhead: You do not have to change the script when you change the data. This reduces the likelihood of regression.
4. Facilitates Non-Technical Contribution: If your stakeholders are non-technical, they can contribute by editing the test data files.
5. Time Efficiency: Running multiple test cases in one is much faster than one at a time, especially in CI/CD.
Common Challenges in DDT
Typical Challenges of Data Driven Testing Overall DDT can have some great advantages it certainly does have some challenges. Here are some commonly encountered problems:
1. Complex Data Management
Generally managing and working with large test data files, particularly with deeply nested structures and formats like JSON can be cumbersome.
2. Debugging Failures
It can be difficult to ascertain the reason for a particular data set failing when one does not have the ability to validate through logging and traceability.
3. Tooling Limitations
Not all frameworks natively support external data-driven architectures, there may be a need for specific adapters.
4. Synchronization Issues
Tests that utilize backend systems like databases or APIs must ensure that the data state is valid and synchronized to the correct stage before execution or evaluation of test once executed and validated.
5. Risks to Security and Privacy
You are already exposed to some risk by having sensitive test data (i.e. passwords or user information) anywhere outside a test environment, and this method will require considerable access control policies be put in place to mitigate that risk.
How to Do Data-Driven Testing(DDT)

In your real world projects, you do not need any complex tools or frameworks. Here is a step-by-step guide using Python, PyTest framework and a simple CSV file as data source.
Step 1: Pick a Perfect Test Scenario
The Most Comparable Scenario: a simple login function called from your code that checks if username and password combination is valid.
Step 2: Test Data Preparation (CSV file)
Create a file called login_data. csv with the content below
plaintext
username,password,expected
admin,admin123,success
user1,wrongpass,failure
test,test123,success
demo,demo321,failureEach row represents a test case.
Step 3: Build the Application Logic (Example)
You are going to test a dummy login function as below
python
# login_system.py
def login(username, password):
valid_credentials = {
'admin': 'admin123',
'user1': 'user123',
'test': 'test123'
}
if username in valid_credentials and valid_credentials[username] == password:
return 'success'
return 'failure'Step 4: Writing Test script with Pytest
You would now write a test script which can read the data from CSV, and run assertions on each row.
python
# test_login.py
import csv
import pytest
from login_system import login
# Utility function to read test data
def read_csv_data(filename):
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile)
return [row for row in reader]
# Parametrize the test with data from CSV
@pytest.mark.parametrize("data", read_csv_data("login_data.csv"))
def test_login_function(data):
result = login(data['username'], data['password'])
assert result == data['expected'], f"Test failed for user: {data['username']}"Step 5: Run the tests
Now run your test suite in the terminal:
bash
pytest test_login.pyPyTest will execute the given test function for each row of data in the csv file, and it will check if the actual matched the expected results.
Output Sample:
bash
test_login.py::test_login_function[data0] PASSED
test_login.py::test_login_function[data1] PASSED
test_login.py::test_login_function[data2] PASSED
test_login.py::test_login_function[data3] FAILEDData File and Test Data
Common Data File Formats:

-
CSV (Comma-Separated Values) – Because of the simplicity and simple integration it carries with itself almost globally used.
-
Excel (XLS/XLSX) – Tabular and human readable formats, almost always the go-to for enterprises.
-
JSON – for structured, hierarchal data.
-
XML – Used mainly in legacy systems or when data is need to be schema validated.
-
Databases – Useful for larger, and/or relational test data sets.
Test Data Characteristics:
-
Input Values: This is the data which is entered into the system under test.
-
Expected Results: Model outputs used for validation
-
Negative Data: Edge cases or invalid inputs to test for resiliency.
-
Boundary Values: Check behavior at the boundaries of valid input ranges.
Expected vs Actual Results

Automated Validation is a big portion of DDT There should be an expected scenario for each test input. The test script should:
-
Read in both the input and expected data
-
Run the test logic.
-
Assuming that the actual response must match with the expected.
-
Log mismatches with enough context.
Limitations of Data Driven Testing

-
Increased Complexity in Test Design
-
Test scripts that read and process data from external sources need to developed.
-
A level of logic for processing different input combinations and validations required is necessary.
-
-
Maintenance Overhead
-
Test data formats may change (i.e., CSV to JSON), or the data format may change, and requires updates to the test framework.
-
Keeping the data files synchronized with any updates to the application can be difficult.
-
-
Debugging Difficulty
-
Debugging can be time-consuming when multiple data sets are failing when you are trying to identify the initial data set that created the failure and scenario when the failure happened.
-
The test logs may become less legible as the test cases are written with some amount of parameterization.
-
-
Initial Setup Time
-
There is considerable time up front to develop a robust data-driven framework as compared to when you use hardcoded test cases.
-
The tester must establish data sources, test data mapping, and execution logic.
-
-
Test Data Management Issues
-
The management of large amounts of test data can become unwieldy.
-
Sensitive data, or the duplication of data, can cause compliance or reliability issues.
Implementing Data-Driven Test Automation
Step 1: Create the function to test
# math_utils.py
def add(a, b):
return a + bStep 2: Prepare test data in a CSV file
Create a file named test_data.csv in your project directory:
plaintext
a,b,expected
1,2,3
0,0,0
-1,-1,-2
5,-3,2Step 3: Write the Pytest test script that reads from CSV
python
# test_math_utils_csv.py
import pytest
import csv
from math_utils import add
# Function to read data from CSV
def load_test_data_from_csv(file_path):
with open(file_path, newline='') as csvfile:
reader = csv.DictReader(csvfile)
data = []
for row in reader:
a = int(row['a'])
b = int(row['b'])
expected = int(row['expected'])
data.append((a, b, expected))
return data
# Load data before test runs
test_data = load_test_data_from_csv("test_data.csv")
# Parameterize the test using the data from CSV
@pytest.mark.parametrize("a, b, expected", test_data)
def test_add(a, b, expected):
assert add(a, b) == expectedStep 4: Run the test
bash
pytest test_math_utils_csv.pyPytest will read the CSV, extract the test cases, and execute the test_add function for each row in the file.
Best Practices of Data-Driven Testing
-
Keep Data and Logic Separate: Don’t couple your test logic with hard-coded values.
-
Use Version Control for Data Files: Support tracking changes over time and helps to avoid regressions.
-
Validate Datasets Prior to Using: Ensure that fields do not have null values and formats are valid.
-
Tag Test Data for Different Environments: Use tags or configuration files to distinguish staging data from production data.
-
Encrypt Sensitive Data: Protect credentials and private data in datasets.
-
Use Logging and Debug Information: Keep track of which data sets failed and the reason why.
Keploy for Data-Driven Testing
Keploy changes the way teams think about data-driven testing. Based on real user interactions it automatically generates test cases and data for your applications. For every interaction Keploy observes, it stores the actual API calls, database calls, and responses from your application, producing an entire suite of test cases without you having to do any manual work.

Follow along with how Keploy delivers these benefits:
Automated Test Generation – Keploy observes real users interactions and translates those into executable test cases with actual data. This completely removes the tedious and time-consuming process you need to use test first strategy to map out the test scenarios and ensures your tests involve actual working patterns users would follow in the real it being validated.
Zero-code Test Creation – Utilization of Keploy allows teams to build huge test suites without ever writing a single test script. The intelligent recording power of Keploy can follow all of the complex routes users are effective when using applications, and automatically produces the relevant test data to be executed with the tests.
Regression Testing – Keploy captures base behavior, enabling regression testing that is significantly more powerful than existing practices. Wherever there has been a change affecting existing functionality, if it does not deviate or change then it will be detected immediately for you and your team, which eliminates the risk of unintentional breaking change issues.
Simple Integration – Keploy integrates into your existing development community seamlessly and offers many options for best integration. It supports existing popular frameworks and requires minimal configuration before you begin generating valuable test cases.
Keploy has huge benefits in testing applications designed using a microservices structure. Keploy’s supports you in understanding the whole chain of interaction instead of the traditional ‘call the service’ strategy where application services are chained together and intermingle in user experience. It captures whatever database calls and third-party API communications are required for each service in the micro-service architecture.
Conclusion
Data Driven Testing (DDT) is more than just a buzzword; it is a common-sense, practical, and efficient alternative to doing software testing in the modern age. DDT separates test logic from test data, and brings a sense of scalability, clarity, and maintainability to your QA efforts. Call it a separate testing strategy from a common practice or just re-distributing your testing methods, whether you are testing complex APIs, enterprise applications, or simple form validations, your testing strategy typically improves by using DDT.
By understanding DDT’s fundamentals, barriers, and best practice implications, your team can embrace the underlying principles of DDT and help future-proof your software systems.
Related Blogs
-
TestNG vs JUnit: Performance, Ease of Use, and Flexibility Compared
-
20 Powerful REST Assured Alternatives for Reliable API Testing
FAQ
-
What are the differences between Data Driven Testing and Keyword Driven Testing?
Data Driven Testing has variation in the Test Data but the Test Logic can stay the same. Keyword Driven Testing has Keywords controlling the flow of execution and our Test Logic could also change based on those keywords.
-
Can I use JSON or XML files for Data Driven Testing?
Yes. JSON and XML are particularly useful when testing APIs or complex nested data structures. Many testing frameworks support JSON and XML as input sources.
-
Is Data Driven Testing only for automation?
While it is primarily used in test automation, DDT can also be used in Manual Testing, since you can refer to structured data to validate different scenarios in order to support the systematic nature of validation.
-
How do I validate expected results in DDT?
Validate actual results against expected results using assertions or comparison functions in your test script based on your test data source.
-
What is Data Driven Testing in API automation?
Sending API requests using data from external files (CSV/JSON) to automatically validate an API response is considered Api DDT. Tools such as Postman, RestAssured and Keploy support this.

Leave a Reply