
Why do some bugs only appear after deployment, even when tests pass locally?
Early in my backend work, I kept hearing discussions around stateful vs stateless. It felt academic at first, but once I started dealing with scaling issues, flaky tests, and production bugs, I saw how much this decision actually matters.
This article is based on how I’ve seen these architectures behave in real systems, not just diagrams.
TL;DR Summary
| Area | Stateful | Stateless |
|---|---|---|
| Memory | Stores session/context | No session memory |
| Scalability | Harder (sticky sessions) | Easy (horizontal scale) |
| Performance | Faster per-session | Slight overhead per request |
| Fault tolerance | Lower | High |
| Debuggability | Tricky (hidden state) | High (explicit inputs) |
| Testing | Complex | Predictable |
| Examples | Databases, sessions | REST APIs, microservices |
What “State” Actually Means in System Design
In simple terms, state is any information a system remembers between requests.
If the system needs to know what happened earlier to respond correctly now, that information is part of its state. Once you start depending on that memory, your system behavior changes in ways that affect scaling, testing, and reliability.
Examples I’ve worked with:
-
Logged-in user sessions
-
Shopping cart data
-
Cached user preferences
-
Previous API calls affecting behavior
If the system needs past data to respond → stateful
If every request is self-contained → stateless
This one difference decides how your system scales, fails, and gets tested.
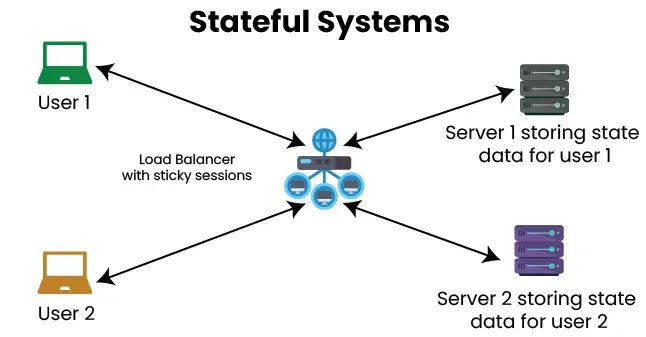
Stateful Architecture Explained (With Real Examples)
In simple terms, state is any information a system remembers between requests.
If the system needs to know what happened earlier to respond correctly now, that information is part of its state. Once you start depending on that memory, your system behavior changes in ways that affect scaling, testing, and reliability.
Examples I’ve worked with:
-
Logged-in user sessions
-
Shopping cart data
-
Cached user preferences
-
Previous API calls affecting behavior
Common real-world examples
-
Session-based login systems
-
Traditional monolithic applications
-
Multiplayer game servers
-
Stateful databases
Why teams choose stateful design
-
Faster response for logged-in users
-
Less data sent in each request
-
Natural flow for step-based workflows
Problems I’ve faced with stateful systems
-
Sticky sessions during horizontal scaling
-
Session loss when a server crashes
-
Bugs that only occur in specific order
-
Hard-to-reproduce production failures
Testing stateful systems always takes more effort than expected.
Stateless Architecture Explained (Modern Standard)
In a stateful architecture, the server remembers information about the client between requests.
That means the way a request is handled often depends on what happened earlier. This can make certain workflows feel smoother, but it also introduces dependencies that aren’t always obvious at first.
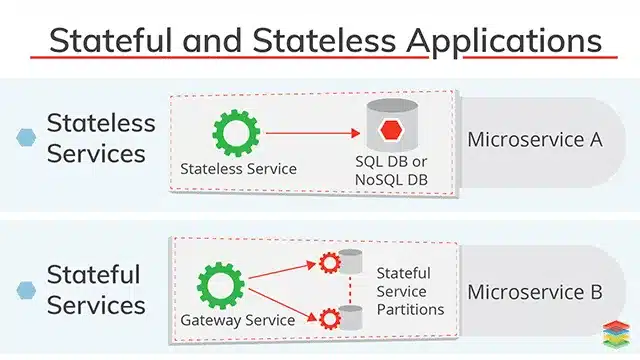
In practice, this usually works like this:
-
A client sends a request
-
The server stores session or context data
-
Future requests rely on that stored information
After the response is returned, the server discards all of this information. The next request starts fresh.
Common real-world examples
-
Serverless functions
-
CDNs
-
Most modern SaaS backends
Why I prefer stateless systems
-
Easy horizontal scaling
-
Server failures don’t affect users
-
Predictable test execution
-
Clean CI/CD pipelines
Trade-offs I’ve seen
-
Larger payload sizes
-
Repeated auth and validation
-
Need strong API contracts
Operationally, stateless systems are simpler to manage.
Stateful vs Stateless: Key Differences That Matter
Scalability
-
Stateful: Needs session affinity and shared storage
-
Stateless: Any node can handle any request
Reliability
-
Stateful: Server failure breaks active users
-
Stateless: Failures are usually invisible
Performance
-
Stateful: Faster for warm sessions
-
Stateless: Slight processing overhead per request
Cost
-
Stateful: Complex infra coordination
-
Stateless: Easier automation and scaling
Stateful vs Stateless Firewalls (Security Example)
Architecture decisions also impact security.
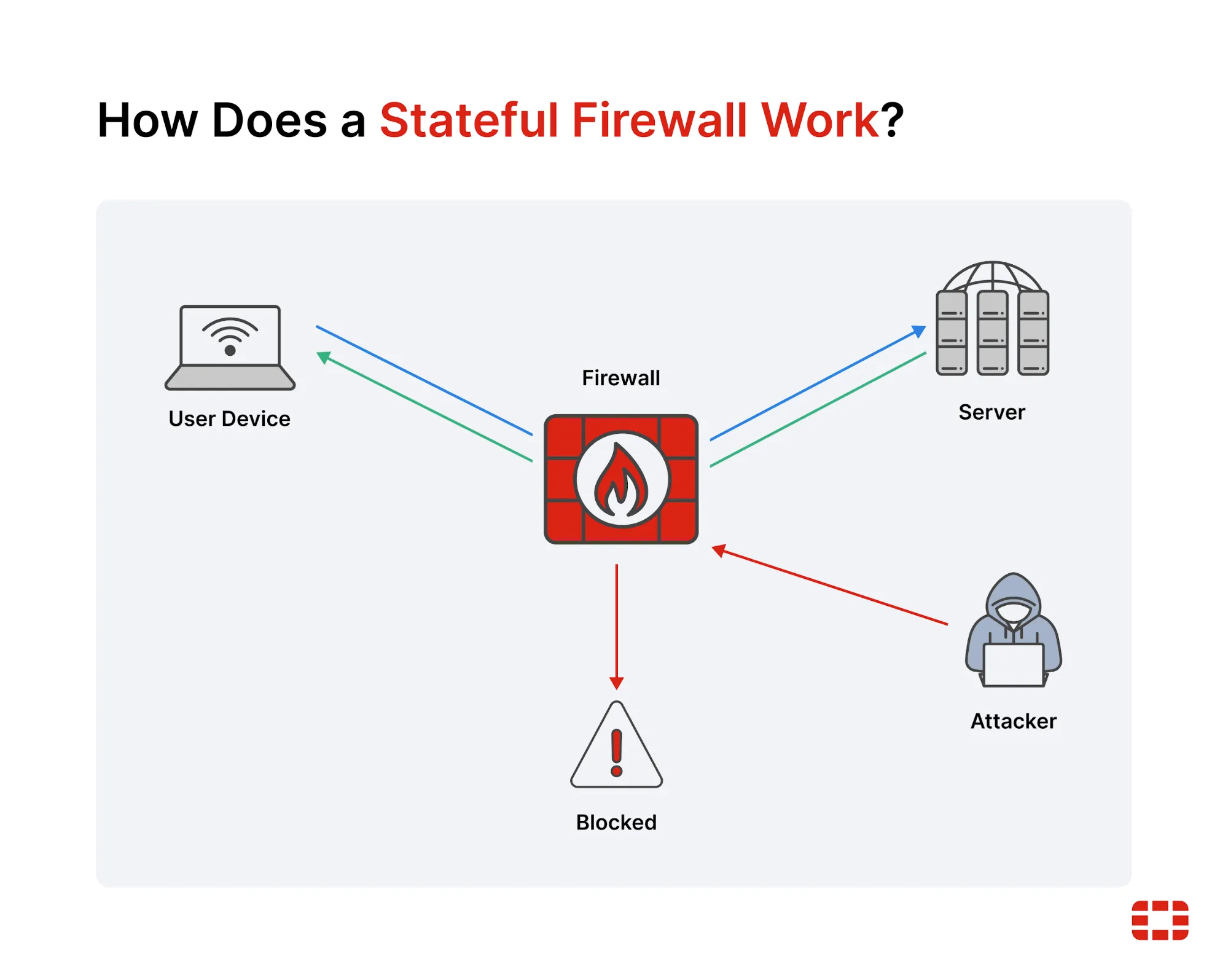
Stateless Firewall
-
Evaluates packets independently
-
Uses IP, port, and protocol rules
Pros
-
Fast
-
Low resource usage
Cons
-
Can’t detect spoofed packets
-
No session awareness
Stateful Firewall
-
Tracks connection state
-
Allows only valid response traffic
Pros
-
Better security
-
Protection against TCP attacks
Cons
-
Higher resource usage
-
More complex to maintain
Security is one area where state clearly adds value.
Authentication: Why Stateless Usually Wins
Stateful authentication
-
Server stores user sessions
-
Cookies map to server memory
Problems
-
Session replication issues
-
Logout inconsistencies
-
Scaling limitations
Stateless authentication
-
JWT or signed tokens
-
All context sent with request
Benefits
-
Zero server memory
-
Easy to scale
-
Predictable behavior
This is why most modern platforms use stateless auth.
Stateful vs Stateless Testing: Where the Real Problems Start
Testing is usually the point where the difference between stateful and stateless systems becomes very obvious.
Things that seem manageable in development start breaking once tests are added to CI pipelines and run repeatedly across environments.
Why Stateful Applications Are Hard to Test
In stateful applications, test results often depend on what happened before. The same request may behave differently based on session data, cached values, or execution order.
From experience, this creates problems like:
-
Difficulty recreating the exact same state for every test run
-
Tests that pass locally but fail in CI
-
Failures that depend on execution order
-
Complex setup scripts just to prepare test data
Maintaining this across environments becomes time-consuming and fragile.
Why Recreating the Same State Is So Difficult
The hardest part is not writing the test, but rebuilding the same state reliably.
Sessions expire, data changes, dependencies respond differently, and small differences between environments cause tests to behave unpredictably. Over time, teams end up spending more effort fixing tests than improving the product.
Record and Replay Testing for Stateful Systems
A more practical approach is record and replay testing.
Instead of manually rebuilding state, real production interactions are captured once and replayed during testing. This includes:
-
API requests and responses
-
Dependency calls
-
Actual data formats and edge cases
This removes guesswork and allows teams to test real behavior, not assumptions.
Tools like Keploy follow this approach by recording real API traffic and virtualizing dependencies and state. This makes it much easier to test stateful applications in local environments and CI without complex setup.
Stateless Testing: Why Automation Works Reliably
Stateless systems are significantly easier to test because each request is independent.
There is no hidden session, server-side memory, or execution history influencing the result. As long as the input stays the same, the response is predictable across environments.
In practice, stateless testing allows teams to:
-
Run tests in any order without failures
-
Execute tests in parallel in CI pipelines
-
Reproduce bugs consistently across environments
-
Avoid complex setup scripts just to prepare state
Because of this, most modern test automation frameworks and CI tools are designed with stateless assumptions. When services stay stateless, testing becomes simpler, faster, and far more reliable over time.
Why Microservices Must Be Stateless
From experience, microservices fail when state leaks between services.
Stateless services:
-
Scale independently
-
Survive deployments
-
Handle traffic spikes better
Hidden state between services is a top cause of production outages.
Testing Impact: Where Architecture Becomes Expensive
This is where the real cost shows up.
Stateful testing issues
-
Test execution order matters
-
Bugs are hard to reproduce
-
CI pipelines become flaky
-
Mocking sessions is fragile
Stateless testing benefits
-
Deterministic test results
-
Parallel execution
-
Easy replay across environments
-
Clear schema and contract validation
Modern testing tools assume stateless behavior.
Why “Stateless” Systems Still Break in Production
Many systems claim to be stateless but hide state in:
-
Caches
-
Async queues
-
Third-party APIs
This invisible state causes production-only failures.
That’s why record-and-replay testing matters. Tools like Keploy capture real production API behavior and replay it in CI, turning hidden state into testable inputs.
Moving from Stateful to Stateless (Real Strategy)
Most teams don’t start stateless. They migrate.
Common steps I’ve seen:
-
Move sessions to Redis or a database
-
Push state into request payloads
-
Add API gateways
-
Use contract-first APIs
-
Add regression replay testing
Cloud platforms made this approach standard.
How I Decide: Stateful or Stateless?
Before choosing an approach, I usually stop and ask myself a few practical questions. These help avoid design decisions that look fine early but cause problems later.
-
Does this request actually need historical data to work correctly?
-
Can the client safely carry the required context without leaking sensitive data?
-
Is this service expected to scale horizontally as traffic grows?
-
How often will we need to replay or debug requests during testing?
Rule I generally follow:
-
UI layers → sometimes stateful, especially for user experience
-
APIs and internal services → stateless by default
Common Myths (What I Learned the Hard Way)
Myth: Stateless systems are always slower
In reality, most latency comes from network calls and database queries. The overhead of stateless requests is usually negligible once traffic increases.
Myth: Stateless architecture is simpler
It’s simpler to operate and scale, but designing it well takes effort. API contracts, validation, and error handling need more upfront thought.
Myth: Stateful systems can’t scale
They can scale, but it often requires sticky sessions, shared storage, and extra coordination. That complexity grows quickly as traffic and teams increase.
Conclusion
From what I’ve seen in real projects, stateless architecture usually works better for most systems.
It scales with fewer surprises, recovers more cleanly when something breaks, and fits naturally into CI/CD and automated testing. These benefits matter a lot once traffic grows or teams start shipping frequently.
That said, stateful design isn’t wrong. It still makes sense for flows that genuinely depend on history. The problem starts when state is added casually and spreads in ways no one tracks properly.
The systems that perform best aren’t fully stateful or stateless. They work because teams set clear state boundaries early and actively remove hidden state over time.
That’s what keeps releases moving fast without creating production issues later.
FAQs
1. Is REST always stateless?
By design, yes. But many REST APIs break this by using hidden sessions or server-side memory.
2. Can stateless systems use databases?
Yes. Storing data is not the same as storing session state. Statelessness applies to request handling.
3. Is GraphQL stateful or stateless?
GraphQL is stateless by design, but resolvers can introduce hidden state if implemented poorly.
4. Which is better for startups?
Stateless architecture is usually better due to lower cost, easier scaling, and faster iteration.
5. Does stateless architecture reduce cloud costs?
In most cases, yes. It enables auto-scaling and efficient resource usage.
6. Are serverless functions always stateless?
They are designed to be stateless. Relying on warm memory creates unpredictable behavior.

Leave a Reply