
I want to share the story of how our team at a fast-paced startup tackled the challenge of API testing without any dedicated QA team, the roadblocks that we encountered, and how we ultimately addressed these issues.
Baseline Challenge
We had 15-day sprints including mandatory unit and API testing.
- Strict Timelines (2 weeks)
- 80% unit test and API test mandate
Initially, we relied on automated testing. Unit tests were stable, but API scripts quickly outdated due to frequent data changes and complex scenarios. Lacking a clear evaluation metric like code-coverage in unit tests, we wanted to cover as many user-scenarios possible for APIs. I suggested the record-replay technique for creating disposable API tests. In short, for API tests I wanted:
- Close to real-world API tests (ideally from prod)
- Easy disposable tests – quickly create/discard
- Automatic Infrastructure spin-up or service/dependency virtualization..
Writing test automation script was not an option since we got only 15 days to ship.

Exploring Various Shadow Testing Approaches
Since we wanted real + disposable test scenarios we thought of directly testing in production, we knew it was risky, but it promised the most realistic test environment..

Pros that we saw with testing in production were:
- Low code approach
- Easy to achieve high coverage
- Discovering unexpected user flows
We started discussions to mirroring live traffic to new versions of our application to compare the responses.
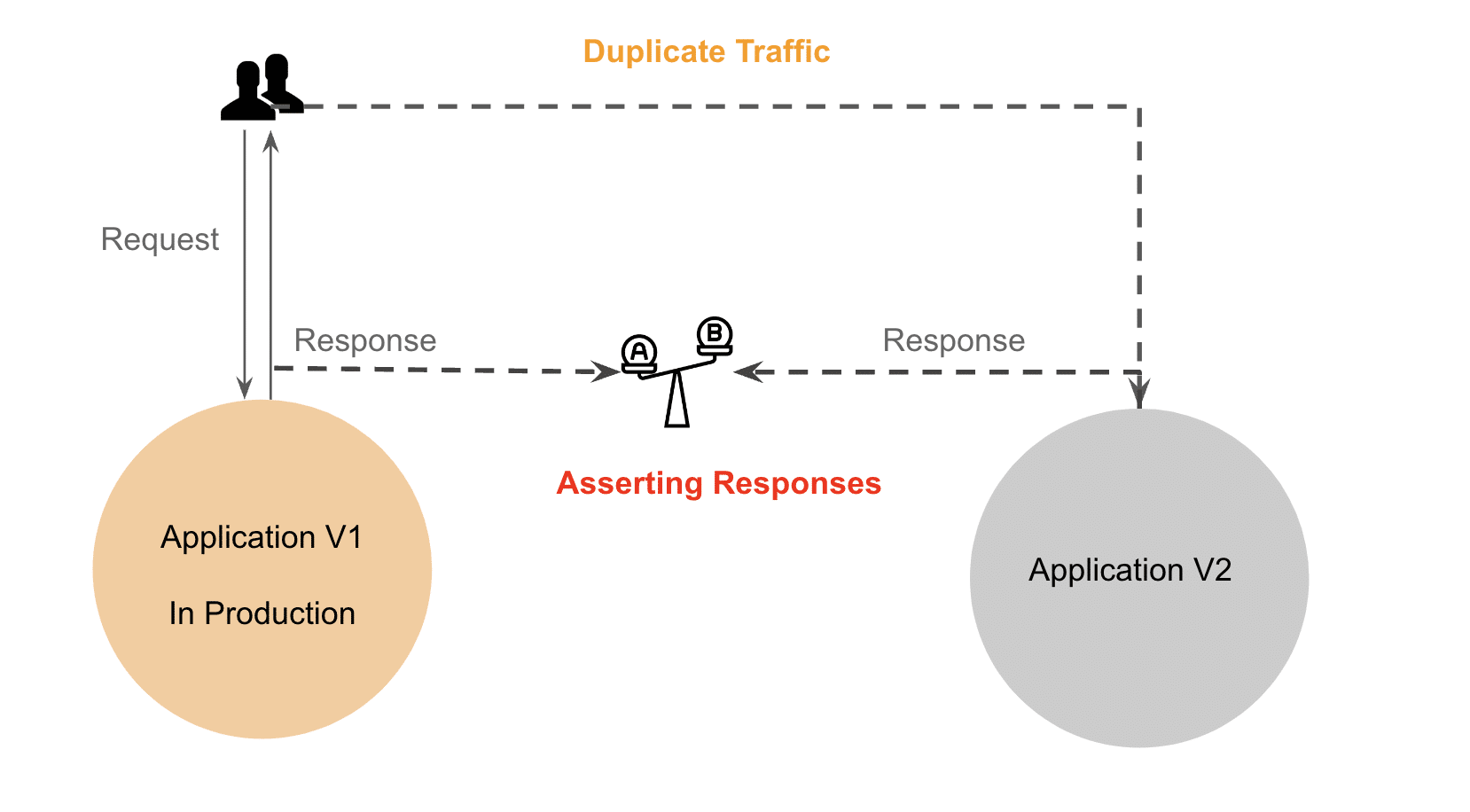
This method was useful for stateless applications but failed to address the complexities of our stateful application, which involved multiple interactions with databases and other services.
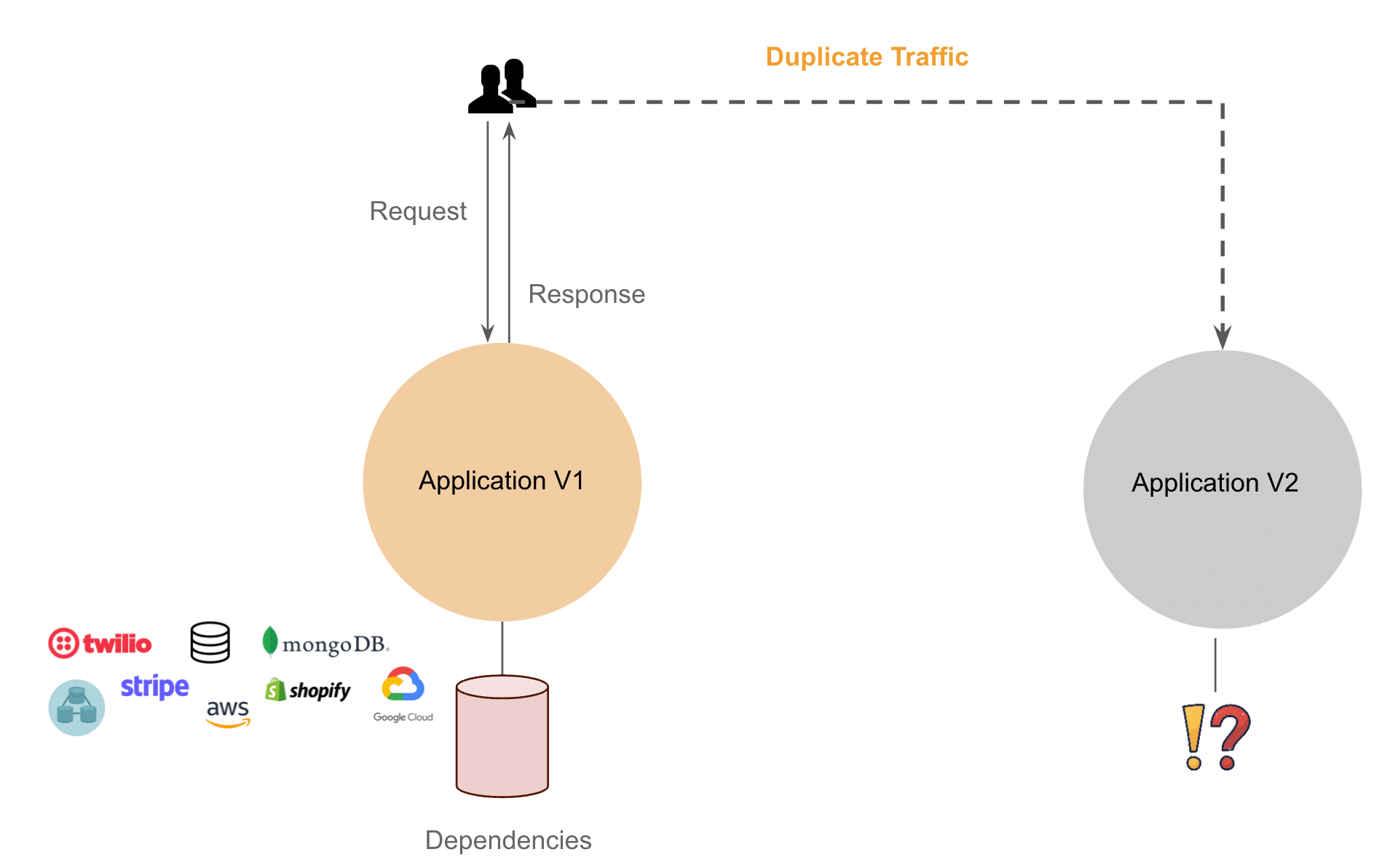
As seen below we rejected the idea in the early discussions, majorly because of the risks involved – all APIs were not idempotent so prod data will be altered if we duplicate traffic, which can lead to downtime or potential data leak or loss.
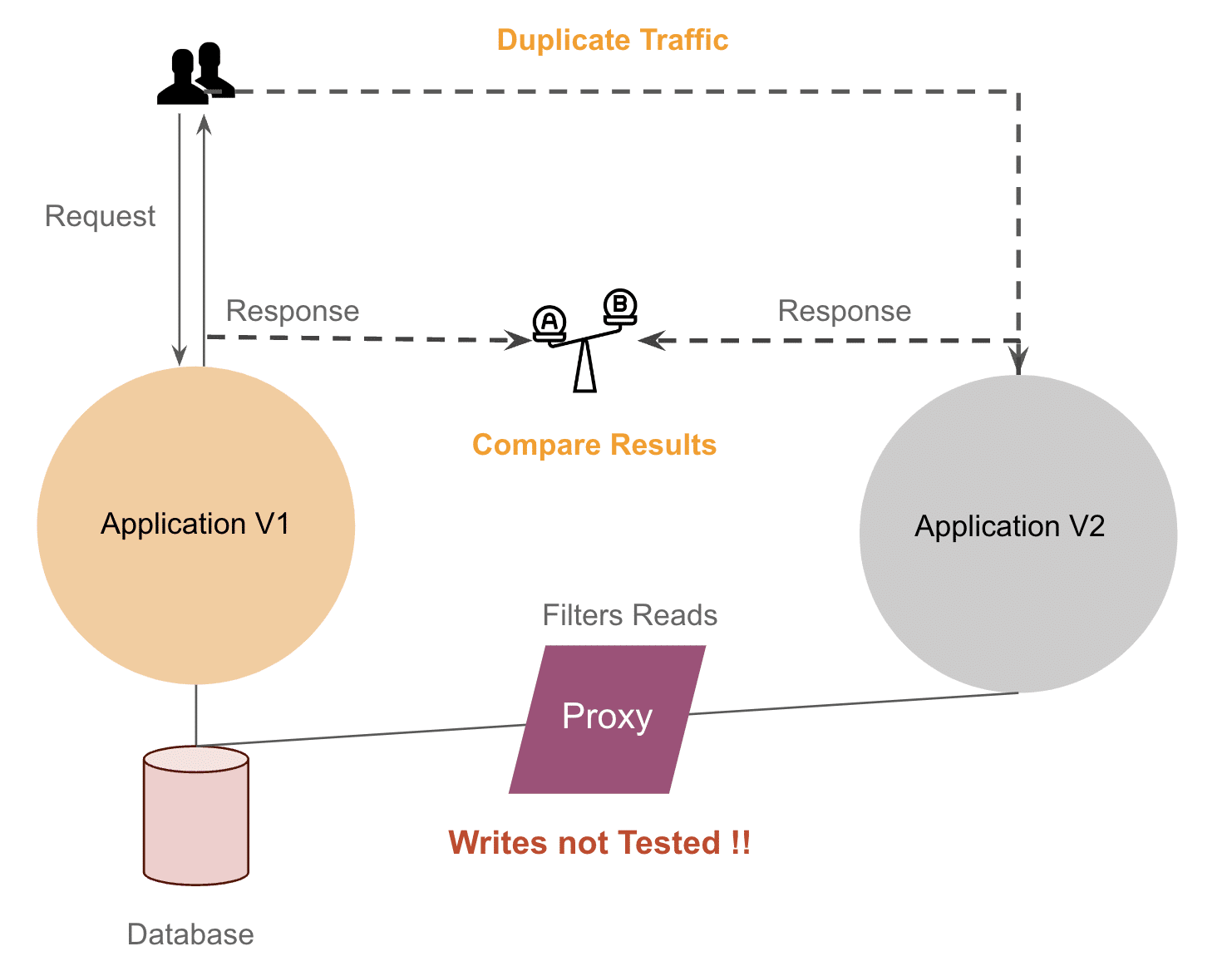
Meanwhile we also discussed replaying just the READ operations by filtering out the WRITE calls with help of a proxy, but that’s not a full proof solution since testing will not be completed. Not worth the effort…
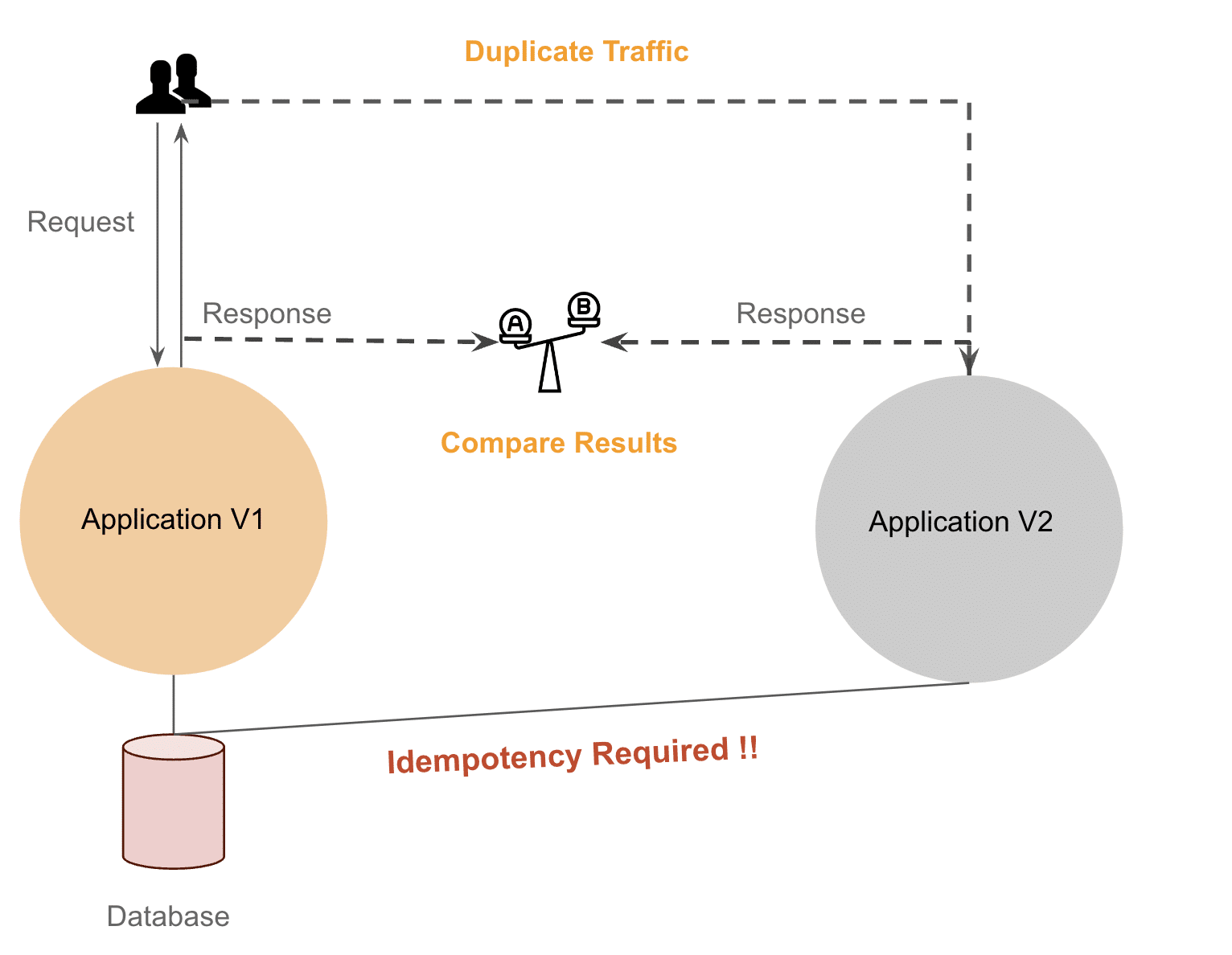
We also thought of maintaining a DB Replica in sync but that was way too expensive and there was a replication lag, leading to additional problems.

Our discussions came down to lower(Non-Prod) environment – Database Replication and Traffic Replay – we IMPLEMENTED THIS!
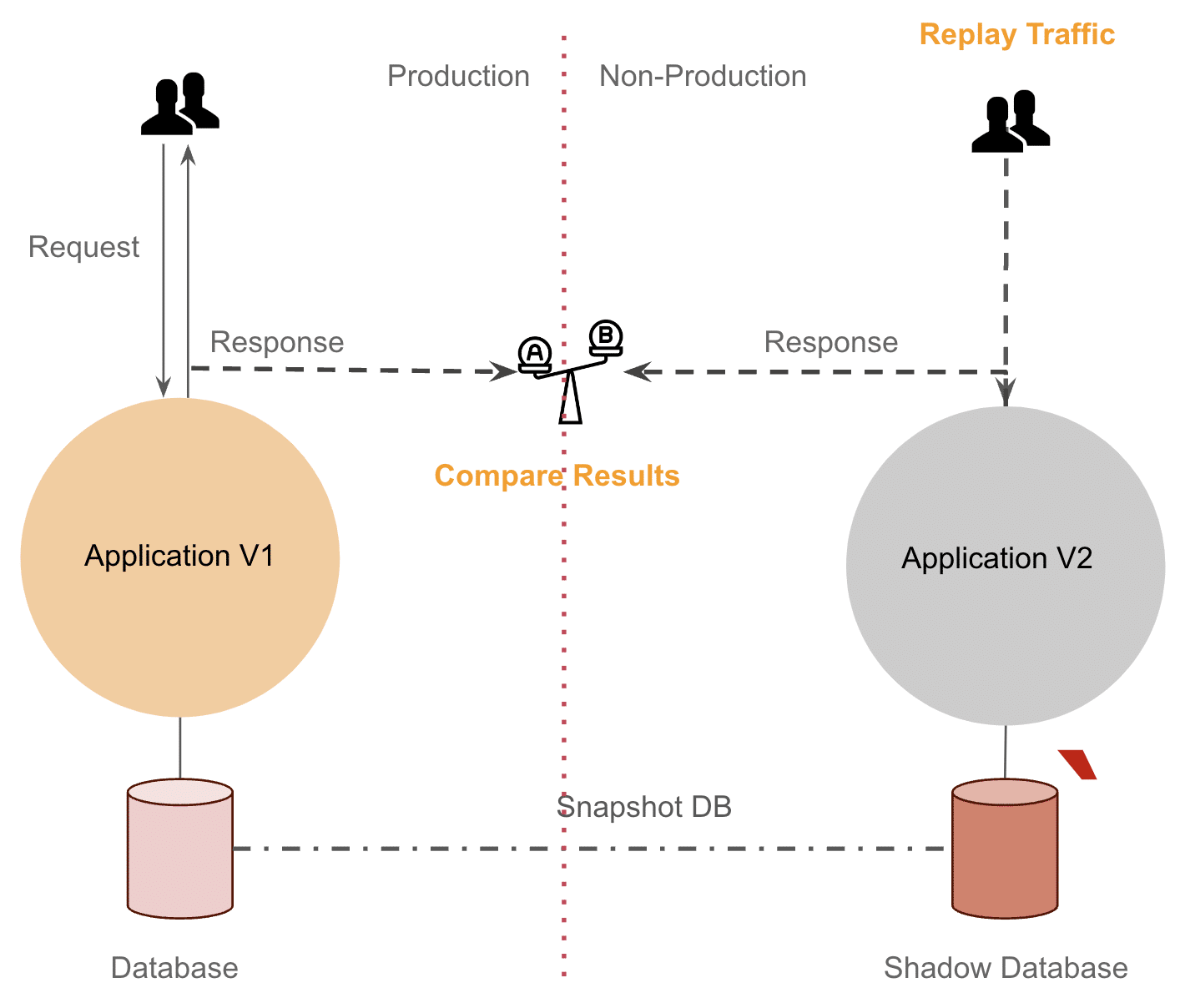
We created a regularly-updating snapshot of prod dB and also tried replaying duplicated 10% of the traffic. While this method allowed for high-fidelity testing, it took a big operational effort, cost of the test environment shot up. We solved 2 of the requirements, however service-infra state challenge remained the same and tests were still flaky.
✅ Close to real-world API tests (ideally from prod)
✅ Easy disposable(quick create/discard) tests
📛 Automatic Infrastructure spin-up works for a simple service but it’s not scalable(Slow and Expensive) where there are multiple services.

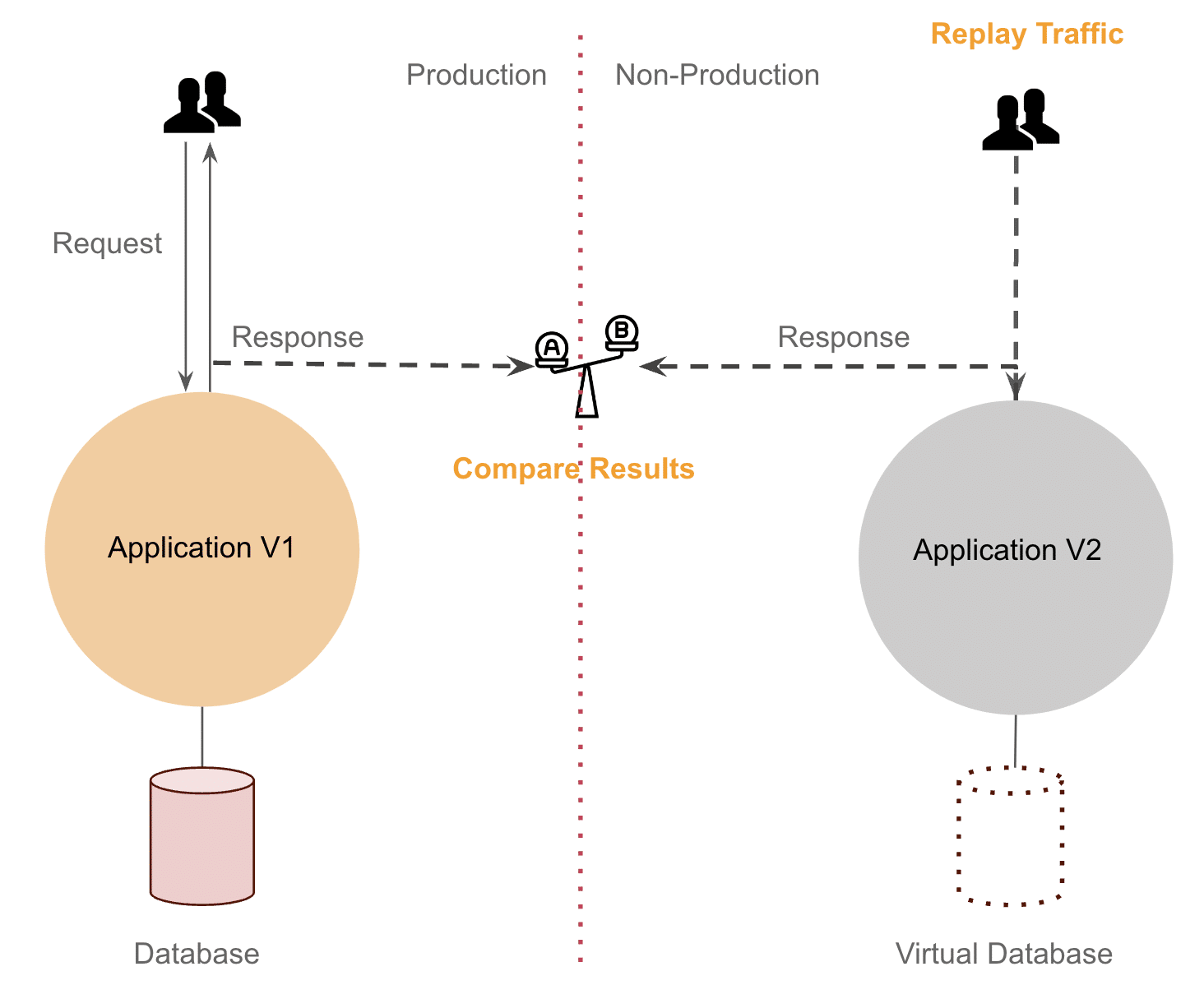
Final approach! – If Database is the problem, get rid of the database!
Record and Replay with Service Virtualisation – Eventually, we realised that we don’t need the complete snapshot and we can just record the particular query being made for that API call. This allowed us to simulate user behaviour accurately and conduct effective tests without the overhead of maintaining a complete database replica. Running our tests became lightweight and cheap.
Developing Keploy
We did explore a combination of open-source tools built to make record-replay testing easier – vcr, and pact, and and wiremock, and a variety of other tried and true projects. There are all great tools for their intended use case but didn’t work for me, these are the shortfalls we encountered –
- VCR: I explored multiple VCR libraries.
- Most require code changes to get integrated.
- Dont support DBs like MySQL, Postgres, Redis, etc.
- The call never went out of the applications and so stubbed out at the client interface level.
- Pact:
- To use Pact, I need to first integrate the SDK on frontend to record the expected contracts.
- Deploy a broker that tracks these recorded contract recordings across environment deployments.
- Then run those tests on the backend, which may fail because I need to also ensure details like Auth are handled – which can again require lots of work to get it to work reliably.
- After all this plumbing and changing my code – The benefit is contract testing. My goal was to achieve more than just contracts – test behaviour.
- Wiremock:
- Again no DBs.
- Correlating incoming calls to outgoing calls is left to the user.
- If I want to record/replay the calls, intercepting or directing calls is also left to the user. I wanted something which can achieve this transparently without application awareness and code changes.
- [Edit] Mountebank – This one is new to me, somehow didn’t pop in my initial research. Got to know from this reddit-comment. Seems to be similar to wire mock though:
- Again no DBs, although there seems to be some provisions to add custom protocols.
- Transparent record and replay not possible. This problem becomes exponentially harder when trying to do for DBs.
- Incoming and outgoing correlation is left to the user.
Since we wanted to record and replay everything (DB, internal/external APIs) at the wire level without code changes – we started writing a different implementation. From these experiences,Keploy open source project was born. Idea was to capture API requests and database responses during normal operation and creates test cases that can be replayed in any environment including CI/CD.
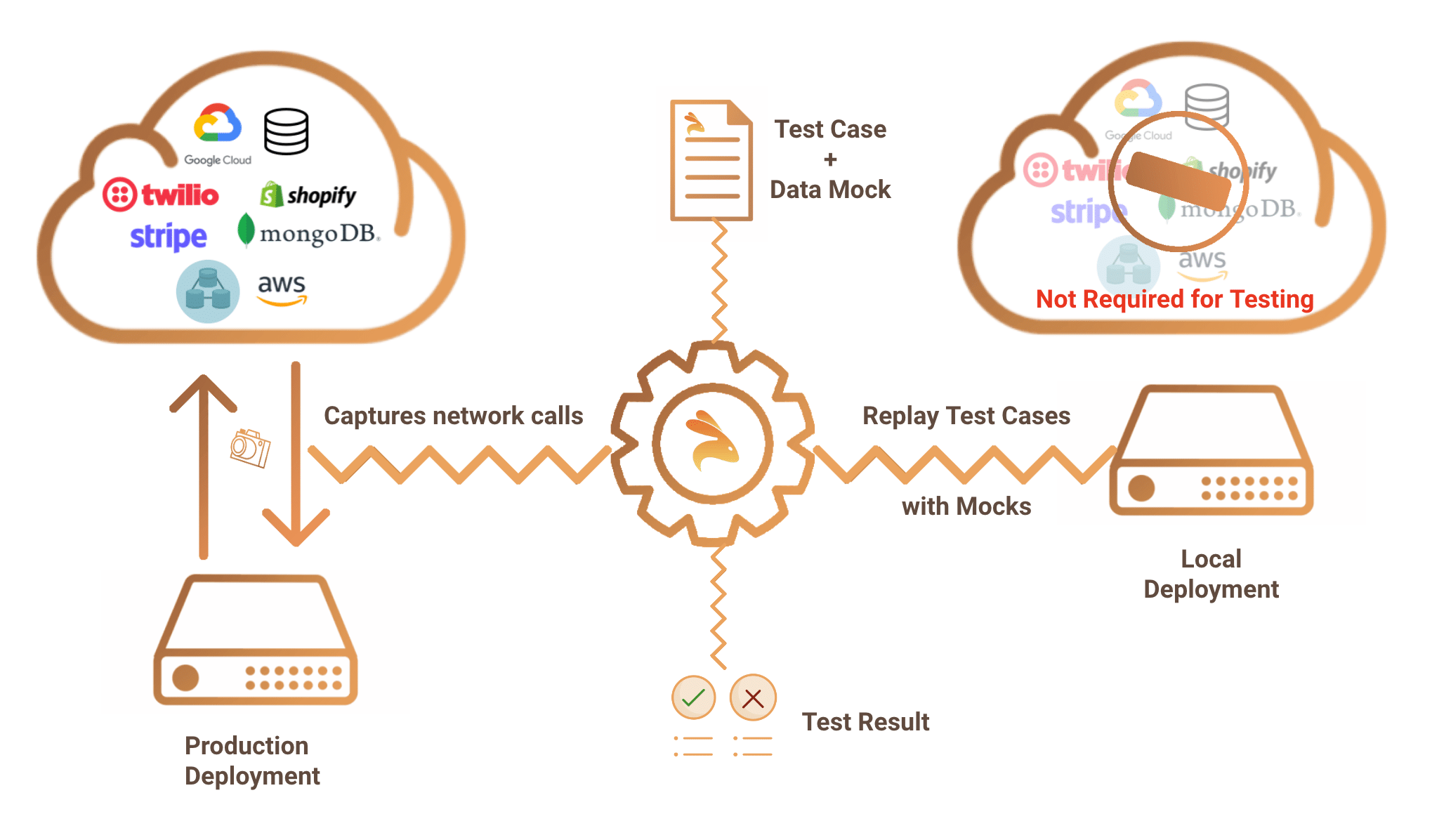
Continuous Improvement
We continue to refine Keploy, aiming to reduce the maintenance burden and increase its adaptability to changes in the application. Our goal is to make API testing as seamless and efficient as possible. One of the hidden advantage with this approach was to identify performance issues. Shadow testing has uncovered hard-to-detect performance issues, such as excessive network calls. For example, we did have usecases where we uncovered some very hard to performance issues.
Eg: Recently one of users recorded the application locally via keploy and saw there were 3000+ Redis mocks for single request to the API. After deeper inspection it was discovered that there was aggregation logic in the application which fetches 3000 entries in separate network calls from the Redis server. This problem is very hard to find locally, because simple lookups are very fast in Redis, there is also no latency locally and Redis also does pipelining. After identifying this, the user converted this to a single batch call. I’m not claiming this to be a performance monitor, but its been very useful to see all the network requests data that my application does to databases and other services to understand what data exchanges are actually happening and also how many 🙂
Limitations of Testing in Production
Since our use case was to mainly use these as regression tests that are initially validated manually, and inform me about changes in application behavior and force me to normalize them if they are expected.
- Adopting production: it might take some time to gain confidence to record from production, but recording API calls locally to create test and stubs also solved the purpose upto good extent. Infact! running these tests locally went quite well because the tests didn’t require any infra spin-up and ran very fast (eg: 1000 test in ~1 min for a medium size app ).
- Effort Required to Develop Parsers for Mocking/Stubbing Out Dependencies: was high. However, it was clear that there can be high confidence on the mocks, if:
- Not done at any library interface level but at the wire level.
- Transparent to the application and without any config/behiviour change to the application.
- Created from recordings of the real Dependency like DBs or other services. I have seen issues with mocks that are manually created and so may not be “realisitic”.
- Update-able easily when the mocked system changes.
- Tested for flakiness
- Over reliance: Developers might become overly reliant on shadow tests to detect regressions. This can lead to issues if the system fails to catch some regressions, requiring a recalibration of expectations. Integration with Code Coverage Libraries to minimize over-reliance has been explored, providing transparency about covered branches in addition to lines of code. Future integration with mutation coverage is also considered.
- Data Privacy: Since shadow testing starts during development, identifying keys related to personally identifiable information (PIi) is crucial. These filters need to propagate to production to maintain privacy
- The Oracle Problem: where determining the correctness of test results is challenging. Can be partially solved by finding duplicate test cases based on branch/line coverage. While it might filter some legitimate use-cases, it saves the users from reviewing 1000s of mostly redundant tests.
- Handling Test Noise: Strategies to handle noise include running tests multiple times to identify inconsistent fields and using techniques like time freezing to prevent session token expiration. https://keploy.io/docs/keploy-cloud/time-freezing/
In my next blog I’ll be writing about our journey of further challenges we faced with the SDK we built to record and replay APIs along with stubs and then moving on to the eBPF approach. The core requirement I had was, how can I iterate quickly with my applications when I make small code changes without having to invest in writing tests scripts and maintaining test data or env. Would love to hear more thoughts 🙂
Invitation to Collaborate
If you find these challenges familiar or are interested in Keploy, we encourage you to join our community. We believe in solving problems together and are eager to share insights and improvements with developers facing similar issues.
This journey taught us the importance of adapting testing strategies to fit the development environment and the invaluable role of automation in maintaining software quality under tight deadlines. Thank you for reading, and we look forward to your feedback and collaboration in making API testing better for everyone.

Leave a Reply