
In the world of software testing, one crucial element often overlooked is Test Data Management (TDM). As development and testing cycles become shorter, automated, and more continuous, the need for efficient management of test data grows. Whether you’re working in Agile, DevOps, or Continuous Integration (CI), having a robust test data management system in place ensures that your tests are reliable, reproducible, and efficient. This blog will explore what test data management is, its importance, best practices, and how Keploy fits into this critical process for modern testing teams.
What Is Test Data Management?
Test Data Management (TDM) is the creation, organization and maintenance of test datasets such that they provide accurate and secure information which meets the governing requirements of the software testing lifecycle by extraction of data, masking of data, anonymizing of data, and copying data to create a test environment which resembles the production environment while protecting confidentiality.
The primary goal of TDM is to provide accurate testing results; comply with data privacy; and minimize the cost of operations by optimally using the data. TDM supports the multiple stages of software testing, enabling rapid feedback during the software development process, and is a vital requirement for modern automated software testing process. Therefore, TDM is important for teams to create reliable and quality software.
Types of Test Data
Test data plays a critical role in evaluating software performance, functionality, and security. Different types of test data help simulate real-world scenarios, validate expected behavior, and identify potential defects across various testing stages.

Choosing the Appropriate Test Data and Following Compliance/Security Guidelines will provide Organizations with a Comprehensive and Reliable/Secure Test Result for Their Software Testing activities.
There are four most Popular Types of Test Data:
-
Positive Test Data
Valid inputs that meet expected conditions and business rules. This data is used to confirm that the system functions correctly under normal and expected scenarios. -
Negative Test Data
Invalid or unexpected inputs designed to verify how the system handles errors, exceptions, and potential security risks. -
Boundary Test Data
Values at the extreme ends of acceptable input ranges, such as minimum and maximum limits. This type of data helps ensure the system behaves correctly at its boundaries. -
Invalid Test Data
Completely incorrect or incompatible inputs used to assess the system’s response to unexpected formats, data types, or values.
Why Test Data Management Matters
Test data are an integral aspect of each stage within any test. It is impossible to have reliable tests without high quality, representative test data; therefore, problems may go undetected in testing due to poor-quality test data. For this reason, TDM is a critical element of any Testing Strategy.
1. Enriching the Ability to Perform Accurately and Consistently Test Data
Flaky tests are frequently generated by inconsistent or incorrect Test Data. Good Test Data management supports creating accurate and repeatable test results by providing every tester with access to the same set of test data when performing the same tests each time they perform them. Good TDM organizes Test Data in a single repository, thereby enabling teams to continue testing with an identical set of test data doing so increases the overall accuracy of the tests performed.
2. Compliance with Regulations and Secure Data Protection
As data privacy regulations and regulatory compliances like GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) are becoming more stringent, it’s critical to protect confidential and sensitive data within a test. Test Data Management (TDM) practices include data masking, anonymizing and encrypting test data so that no confidential or sensitive data is made available during the testing process. Organisations that implement TDM practices generally comply with the regulations and simultaneously utilise realistic Test Data.
3. Automated Test Data Provisioning and Management Accelerate Testing Cycles
Manually provisioning and configuring data can significantly extend the length of the testing cycle. Automated test data provisioning and management allow test cycles to occur considerably faster. This is critical in Agile development environments, where time to market is essential. Automated TDM tools will always have test data available, thus decreasing the number of delays caused by not having data and increasing the overall speed of testing.
4. Automated Test Data Provisioning and Management Enable Shift-Left Testing
Shift-left testing refers to an approach for conducting testing earlier in the development process. This methodology relies heavily on the availability of test data. By having access to test data early on in the software development lifecycle, development and testing teams can detect problems and defects earlier in the process, resulting in a more efficient use of resources and ultimately less time wasted in the future.
Core Components of Test Data Management
- Test Data Planning
A test data plan provides a detailed roadmap for managing test data throughout the entire testing cycle; it will help create a more efficient process and save time and resources in the long-term through efficient use of IT test environments.
To develop a comprehensive test data plan requires the following considerations:
-
What types of data are required for each of the test scenarios
-
How much data will be needed for each test scenario
-
What types of data will be used (e.g., real, synthetic, or anonymized)
-
Any dependencies between the different datasets required to execute the tests.
By properly creating a test data plan, you can effectively respond to the various data needs associated with testing and minimize the complexity associated with meeting those needs.
- Test Data Creation
There are multiple methods to generate test data. The sources for creating test data can be:
-
Using the data that comes from the production environment, although this data is actual data being generated within a company’s day-to-day operations.
-
Using synthetic data that is generated automatically to simulate how real data will behave.
-
Using a smaller representative example (sample) of production data but may include both a small portion of it as well as being less complete than actual production data.
There are benefits and negative aspects of using production data and synthetic data; however, synthetic data tends to be more flexible and less dependent on the actual physical environment, whereas production data has a much higher level of integrity, but includes sensitive information.
- Anonymization and Masking of Data
When testing with actual production data, there is an increased risk that sensitive data could inadvertently be exposed (e.g., through a browser window, etc.). Therefore, data masking and anonymization are critical parts of test data management that help teams maintain the privacy and security of sensitive data, including personally identifiable information (PII) or finance-related information. In addition, these practices also allow for team members to conduct their testing using "realistic" data but keep sensitive data non-disclosure protected.
- Provisioning of Data
Provisioning of data refers to providing testing environments with access to appropriate data sets during testing. Historically, this was a highly manual, labour-intensive process that had many potential errors. By automating this process, teams can greatly reduce the cycle-time when performing tests. CISOs can leverage tools such as Keploy to enable automated provisioning of data sets in their respective CI/CD application workflow, thus ensuring that testing teams will always have access to required data sets when required.
- Refresh and Version Control
Test data often changes as the application evolves. As new features are added or bugs are fixed, the data required to test those features also changes. Keeping test data current and versioned ensures that the tests remain relevant and can be easily reproduced if needed. Automated systems can refresh and version test data, ensuring that tests are always run on the most up-to-date datasets.
The most effective method for managing your test data is to:
1. Create and use automated test data generation
It takes a lot of work to create and maintain test data by hand. In addition, creating and maintaining test data manually leads to a high level of error. You must spend time ensuring that you have sufficient test data available for use whenever you want, as well as ensuring that your test data meets the requirements of your tests. By integrating Keploy to automate your test data generation in an automated testing pipeline, you will have the ability to generate your test data seamlessly, without needing to do any manual work on your part.
2. Centralize the location of your test data
If all teams and testers can access a central repository of test data, this makes it much easier for the teams to manage the test data. Because all teams and testers will have access to the same test data, they will have less of a chance of getting mixed up with different versions of the same test data. By using a central repository of test data, you will also be able to implement version control on your test data, which will allow you to easily recreate any test data you previously created.
3. Employ Data Masking / Privacy Controls
To comply with privacy regulations, it is important to mask or anonymize the sensitive data in your test datasets. This way, teams can create production-like data, without putting real identifiable personal information at risk. One best practice for masking sensitive data is to create random values for the fields that are sensitive, while at the same time retaining the structure and format of the original data that was created.
4. Integrate Test Data Management with CI/CD
To ensure that testing is always performed using the same set of test data, TDM should be automatically provisioned in the CI/CD pipeline. This means that no matter if a developer is building an application on their own workstation or if the application is being deployed into an environment resembling production, the test data will always match what the developers want to test against. By integrating TDM into your CI/CD process, you can eliminate delays and provide consistent test data.
5. Version and Track Test Data
Version control of test data is critical because as software continues to change and evolve, the amount of test data required to properly evaluate the software will also change and evolve. A good versioning system allows your team to maintain an archived history of the test data, giving you the opportunity to revert to a previous version if necessary. Versioned test data also helps to ensure reproducibility, which is vital for finding and fixing defects, conducting ongoing testing, and producing effective CI/CD results.
Test Data Management Obstacles
While the advantages of Test Data Management (TDM) exist, there are multiple obstacles related to TDM:
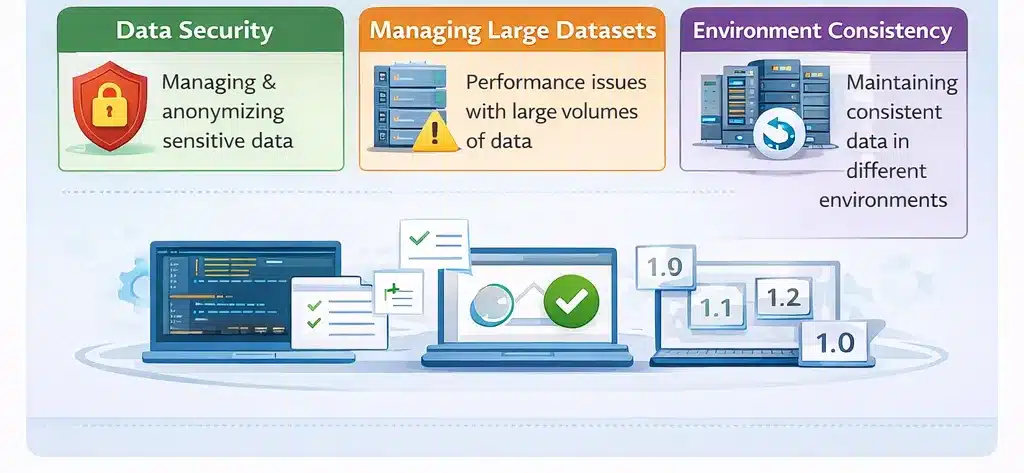
-
Data Security: Managing/Masking/Anonymizing sensitive information is a challenge within large data sets.
-
Managing Large Datasets: Storing and managing very large amounts of test data may cause performance issues related to improper data indexing and/or optimization.
-
Environment Consistency: There are challenges around ensuring that test data is consistent across various environments such as development, staging, and production, especially when you have data dependencies.
How Test Data Management Fits With Keploy

Keploy simplifies Test Data Management (TDM) by improving workflows across test data generation, test case creation, and automated testing. It helps teams reduce manual effort by capturing real application behavior and converting it into reliable test artifacts.
With Keploy, teams can automatically create production-like synthetic replicas of real environments. This approach enables realistic test data generation without exposing sensitive production information, making the process faster, safer, and more efficient.
By providing tools to create, manage, and reuse synthetic test data, Keploy ensures consistency and reliability across test runs. This allows developers and QA teams to spend less time maintaining test data and more time focused on building, validating, and shipping high-quality software.
Common Misconceptions About Test Data Management
"We can always use production data"
Testing with production data and using an unprotected production database to test applications is dangerous because it exposes sensitive personal data and puts companies at risk of being in violation of state and federal privacy regulations (i.e. HIPAA, PCI, etc.). While production data can help you create realistic test cases, production data should be encrypted, masked, or anonymized before you use it to create test data.
"Test data generation is only for large teams"
While it is true that the structured creation, management, and reutilization of synthetic test data has become more efficient due to increased use of TDM tools and practices, TDM is a viable solution for any team—small, large, or otherwise—will benefit by having structured, comparable, repeatable data to validate their testing. Automated provisioning of synthetic test data allows smaller teams to focus more of their efforts on actual testing, rather than managing test data.
Future Trends in Test Data Management
-
As artificial intelligence evolves, it will become easier to create synthetic test data. Therefore, the test data generated with AI will be more accurate and diverse than data generated traditionally.
-
The ability of testing organisations to self-manage their data will increase through web-based portals, thus providing testers the ability to manage and request data as needed.
-
Increased Privacy, Due to growing concerns regarding data privacy, the focus on test data management is shifting towards protecting sensitive information through the implementation of privacy enhancement technologies such as data encryption and data masking.
Conclusion
To be effective, test data management solutions must provide a high degree of precision, security, and efficiency for test processes, and this requires the automation of data provisioning, a focus on protecting sensitive information, and consistency among environments. Keploy provides test data generation tools to ensure that every test will always complete with quality, secure, and consistent data, thereby allowing organisations to develop high-quality software faster.
Explore how Keploy can help you streamline your test data management and improve your software testing processes today.
Frequently Asked Questions (FAQ)
1. What is Test Data Management in software testing?
Test Data Management or TDM is the management process of creating, organizing, securing, and maintaining Test Data in the course of the Software Testing lifecycle. TDM provides Testers with accurate, compliant, and production-like data while also protecting sensitive information.
2. Why is it necessary to implement Test Data Management?
Bad or inconsistent test data will lead to inaccurate test results, undetected problems, and unreliable tests. Therefore, implementing Test Data Management (TDM) will enable improved accuracy in testing, automation of testing, compliance with data privacy regulations, and faster testing cycles during Agile and Continuous Integration/Continuous Delivery (CI/CD).
3. What are some of the most commonly utilized types of test data?
The following are some of the most commonly used types of test data during the process of testing: Positive Test Data, Negative Test Data, Boundary Test Data, and Invalid Test Data. All of these different types of test data can help testers determine how well the system responds to valid inputs, edge cases, and invalid inputs.
4. Can production data be used for testing?
You can utilize production data for testing purposes once it is properly masked, de-identified or encrypted. It is unsafe and potentially violates privacy laws like GDPR/HIPAA to use raw, unmasked production data. Synthetic or de-identified test data is typically more suitable for testing than raw production data both in terms of safety and scalability.
5. What is synthetic test data?
Synthetic test data is data that has been generated based on the behaviour of real production data but does not contain any personally identifiable information (PII). Synthetic test data is very adaptable to different environments such as automated testing and CI/CD Pipeline, and very scalable when needed.

Leave a Reply