
The principles of software testing are the foundation of building reliable software. I’ve seen teams write thousands of test cases and still miss critical bugs in production. The problem is rarely effort – it’s direction.
The software testing principles help teams focus on risk, prioritize effectively, and avoid wasted testing effort. Instead of chasing coverage blindly, they shape how software testing should be approached at every stage of development.
What are the Principles of Software Testing?
The principles of software testing are seven fundamental guidelines that help teams decide what to test, how much to test, and where to focus their effort. Defined by the International Software Testing Qualifications Board (ISTQB), these principles are not step-by-step rules – they’re a way to think about testing. They shape decisions around test planning, test design, defect tracking, and coverage prioritization.
Quick Summary of the 7 Principles
| Principle | Key idea |
|---|---|
| Presence of defects | Testing shows bugs exist, not that they don’t |
| Exhaustive testing | You cannot test everything |
| Early testing | Fix bugs earlier to save cost |
| Defect clustering | Most bugs are in a few modules |
| Pesticide paradox | Tests must evolve over time |
| Context-dependent | Testing varies by product |
| Absence of errors fallacy | Bug-free ≠ useful |
The 7 principles of software testing

1. Testing shows the presence of defects
Testing proves bugs exist. It cannot prove they don’t.
Even if every test passes, that only means no bugs were found under the conditions you tested. It says nothing about the conditions you didn’t test. Passing tests are a signal-not a guarantee. This is why teams focused on production reliability often combine testing with monitoring and real-world validation, not just a green CI pipeline.
2. Exhaustive testing is impossible
You cannot test every possible input. Even a simple system has millions of input combinations. Trying to cover all of them leads to bloated test suites and slow pipelines with diminishing returns.
The answer is prioritization:
-
Risk-based testing
-
Critical user journeys
-
Edge cases that actually matter
A smaller, well-designed suite consistently outperforms thousands of redundant tests.
3. Early testing saves time and money
The earlier a bug is caught, the cheaper it is to fix. Defects found in production can cost significantly more to resolve than those caught early – that gap is real and well-documented.
Testing shouldn’t be a phase that happens after development. Write tests alongside code. Validate requirements before they become features. Run tests in CI so feedback comes in minutes, not days.
Teams at Google are known for emphasizing early testing and continuous integration to reduce the cost and impact of late-stage defects.
4. Defect clustering
Most bugs don’t spread evenly across a codebase. They cluster. Around 80% of defects tend to come from roughly 20% of the code-usually the most frequently changed modules, complex business logic, or legacy systems nobody wants to touch.
These are usually:
-
Frequently changed modules
-
Complex business logic
-
Legacy systems
If you know where bugs have appeared before, test there more. Analyze defect history, identify the modules that fail repeatedly, and weight your coverage accordingly.
This aligns with the Pareto principle, where a small portion of the system is often responsible for the majority of defects.
5. The pesticide paradox
Run the same tests long enough, and they stop finding new bugs. The system has essentially been vaccinated against those specific checks; anything they would have caught has already been fixed.
To keep tests useful: update them as the product evolves, add scenarios based on recent changes, and mix automation with exploratory testing. Exploratory testing follows no script, which is exactly why it finds things automated suites miss.
6. Testing is context-dependent
A banking app and a marketing landing page need very different testing strategies. Applying the same approach everywhere wastes effort on low-risk areas and under-tests the critical ones.
What matters:
-
User impact
-
Risk level
-
Compliance requirements
-
Release cadence
The strategy should match the stakes.
7. Absence of errors is a fallacy
A system with no known bugs can still fail users. If the product doesn’t do what users actually need, it doesn’t matter that all tests passed.
Testing should validate usability alongside functionality-acceptance testing, real user feedback, and occasionally asking whether you’re building the right thing at all.
How these principles apply across testing stages
| Stage | Focus | Key principles applied |
|---|---|---|
| Unit testing | Individual components | Early testing, pesticide paradox |
| Integration testing | Module interaction | Defect clustering |
| System testing | Full system validation | Context-dependent |
| Acceptance testing | User validation | Absence of errors fallacy |
Unit testing
Unit tests are where early testing and the pesticide paradox show up most clearly. Writing tests during feature development catches logic errors before they reach higher layers. Keeping those tests updated matters equally-unit tests tied to old business logic become noise fast.
Integration testing
This is where most real failures surface: API mismatches, unexpected data shapes, timing issues between services. Defect clustering usually points here. If you’re deciding where to invest testing effort, integration boundaries are a reliable starting place.
System testing
Full-system validation needs to match real-world conditions-load, environment, usage patterns. A payment flow needs more rigor than a static content page. Context shapes what "enough testing" actually means at this level.
Acceptance testing
Acceptance testing answers a different question than the others: not "does it work?" but "does it work for users?" All tests can pass and users can still fail. That’s the absence-of-errors fallacy in practice.
The pillars of software testing
The seven principles guide how to think about testing. The pillars describe how to execute it day-to-day.
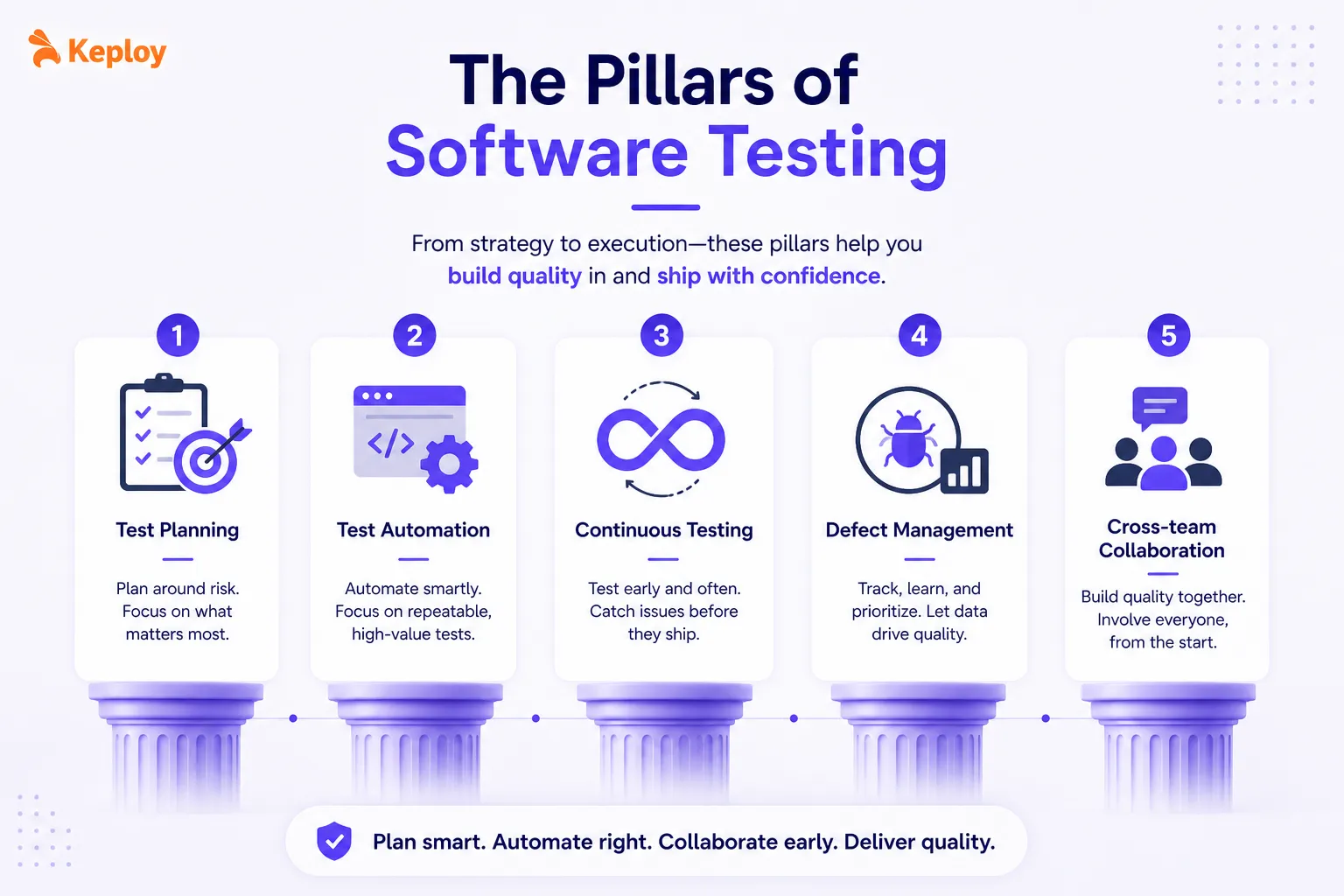
1. Test planning
Testing without a plan drifts-you end up covering what’s easy rather than what matters. A good plan defines scope, high-risk areas, critical user flows, and what "done" looks like.
For a payment system, that means transaction accuracy, failure handling, and security checks first. Everything else second.
2. Test automation
Automation reduces repetitive effort and makes testing consistent. But it has to be applied strategically-automating everything leads to the same problems as testing everything: slow pipelines, high maintenance, and coverage that doesn’t reflect risk.
Focus automation on regression scenarios, critical workflows, and tests that run on every commit.
3. Continuous testing
Testing integrated into CI/CD means every code change gets validated before it ships. Feedback comes in minutes instead of days. Regressions get caught before they reach production.
This isn’t just a tooling choice-it requires teams to treat test failures as blockers, not as noise to dismiss.
4. Defect management
Bug tracking isn’t just about fixing what’s broken. Done well, it’s a data source. Defect history tells you which modules fail most often, where coverage gaps exist, and where risk is concentrated. That data should feed back into test planning.
5. Cross-team collaboration
Quality isn’t owned by QA. When developers, QA engineers, and product managers work in silos, defects get discovered late, and context gets lost between handoffs. Getting everyone involved in requirements, not just reviewing changes, determines what gets caught and when.
How Teams Put the Pillars into Practice
Defined processes are useful. Workflows that run without thinking are better.
Teams that apply these pillars well embed testing into daily development:
-
Test cases get written during feature work
-
Critical scenarios get identified in sprint planning
-
CI pipelines run on every push.
-
Testing stops being a separate phase and becomes part of how the work gets done.
Real-world usage is also an underused input. Traditional testing relies on assumed scenarios. Actual production behavior surfaces edge cases nobody thought to write test cases for-API responses that differ from the docs, usage patterns that reveal unexpected load, failures that only happen in specific sequences.
Teams that feed production data back into their test suites tend to find coverage gaps they didn’t know they had.
In high-frequency deployment environments, teams often rely on automated validation to catch issues early – especially when changes hit production multiple times a day.
Supporting execution with the right tools
Even with good processes, maintaining test quality at scale is hard. As systems evolve, keeping test cases in sync with changing APIs, avoiding duplication, and making sure coverage reflects real usage are ongoing problems.
Tooling helps, not as a substitute for strategy, but as a way to reduce manual overhead.
Tools like Keploy generate tests from actual API traffic, which is useful in integration-heavy systems where behavior changes frequently and writing tests by hand can’t keep pace.
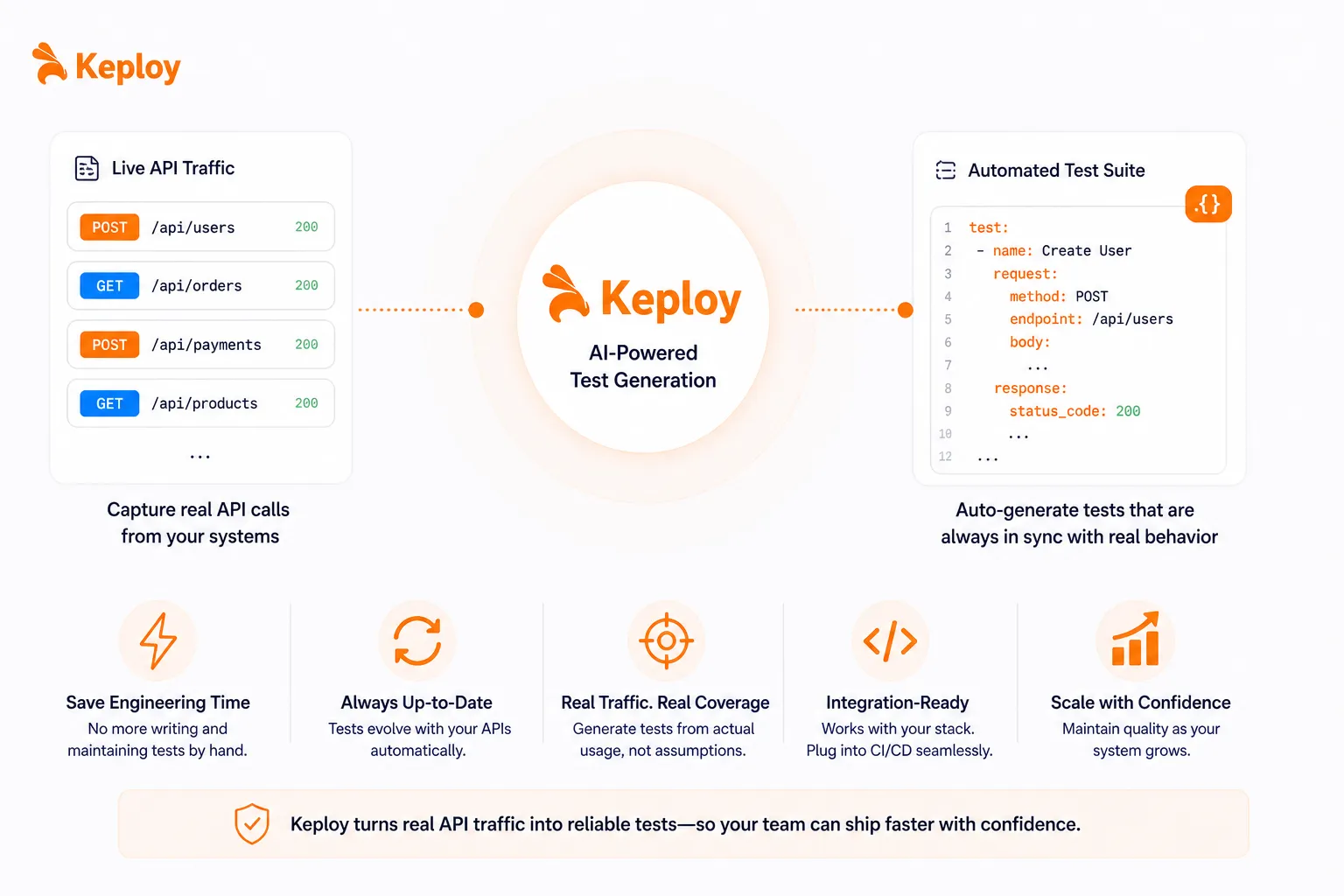
Common Mistakes Teams Make (and how to fix them)
Even teams that understand the principles often break down in execution. Usually, because they’re measuring activity instead of impact.
1. Measuring quality by test count
More test cases don’t automatically mean better quality. They often mean slower CI, more maintenance, and duplicate coverage that wasn’t worth writing, exactly what the exhaustive testing principle warns against.
Why this happens:
-
Pressure from coverage metrics
-
Focus on quantity over impact
The fix:
-
Prioritize critical user journeys
-
Remove redundant tests regularly
-
Measure defect detection, not test count
2. Ignoring high-risk areas
When testing effort spreads evenly, critical parts end up under-tested.
The fix:
-
Analyze defect history
-
Identify failing modules
-
Focus testing on high-risk areas
3. Not updating test cases over time
Outdated tests are the pesticide paradox in action-they only catch patterns the system has already been fixed for.
The fix:
-
Schedule periodic test reviews
-
Remove obsolete tests
-
Add scenarios based on real usage
4. Delaying testing until late stages
When testing happens after development, late defects are expensive and often require architectural changes that earlier feedback would have avoided.
The fix:
-
Involve QA early
-
Validate edge cases before coding
-
Run tests in CI pipelines
5. Applying the same testing strategy everywhere
Different products have different risk profiles, compliance requirements, and release cadences.
The fix:
-
Adjust based on product complexity
-
Consider user impact
-
Match testing to risk
6. Assuming "all tests passed" means "ready to ship"
A green test suite is reassuring. It’s not a guarantee.
The fix:
-
Combine automation with exploratory testing
-
Monitor production behavior
-
Collect user feedback
7. Treating QA as a separate function
When QA is siloed, feedback loops slow down and bugs are discovered late.
The fix:
-
Align developers, QA, and product early
-
Define shared acceptance criteria
-
Treat quality as a team responsibility
Conclusion
The seven principles don’t tell you what tests to write. They tell you how to think about testing-where to focus effort, when to push harder, and when you’re heading the wrong direction.
Teams that actually apply these principles tend to have smaller suites that catch more bugs, faster feedback loops, and fewer surprises in production. They’re easy to understand. The hard part is letting them actually change how you work.
FAQs
What are the principles of software testing?
Seven guidelines from ISTQB that help teams design effective, risk-based testing strategies. They’re decision-making frameworks, not step-by-step rules.
Why are software testing principles important?
They help teams avoid wasted effort, find defects early, and focus testing where it actually matters, rather than spreading effort evenly and hoping for the best.
What is the pesticide paradox?
Repeated tests stop finding new bugs over time. The system effectively gets immune to them. Test cases need to evolve as the product does.
Is exhaustive testing possible?
No. The number of possible input combinations in any real system is too large to test completely. Risk-based prioritization is the only practical answer.
How do these principles apply in agile?
Early testing and defect clustering map naturally onto sprints: validate early, find where bugs cluster, and address them within the same iteration rather than carrying them forward.

Leave a Reply